这篇文章上次修改于 475 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
查询处理概述
三步骤:
- 查询解析:将查询语句转化为容易被数据库执行的表达
- 查询优化:为优化查询的执行计划而进行各种逻辑等价的转换
- 查询执行:查询的实际执行
查询解析
通过SQL语句,生成查询树
- 词法分析:提取SQL语句关键词,常量等成分
- 语法分析:词法分析的成分构建一个语法分析树
- 语义分析:检查语法分析树的语义正确性,并将其转化为基于关系代数式表达的查询树
查询优化
根据查询树,获取物理执行计划
- 逻辑优化:依赖于逻辑等价变换为更高效率形式
- 代价估计:预测多个执行计划的资源代价
- 物理优化:根据代价选取最小消耗的计划
查询执行
运行执行计划,返回查询结果
- 计划编译:转化为可执行代码,将执行结果返回。
- 计划执行:通过并行技术,编译技术提高执行效率。
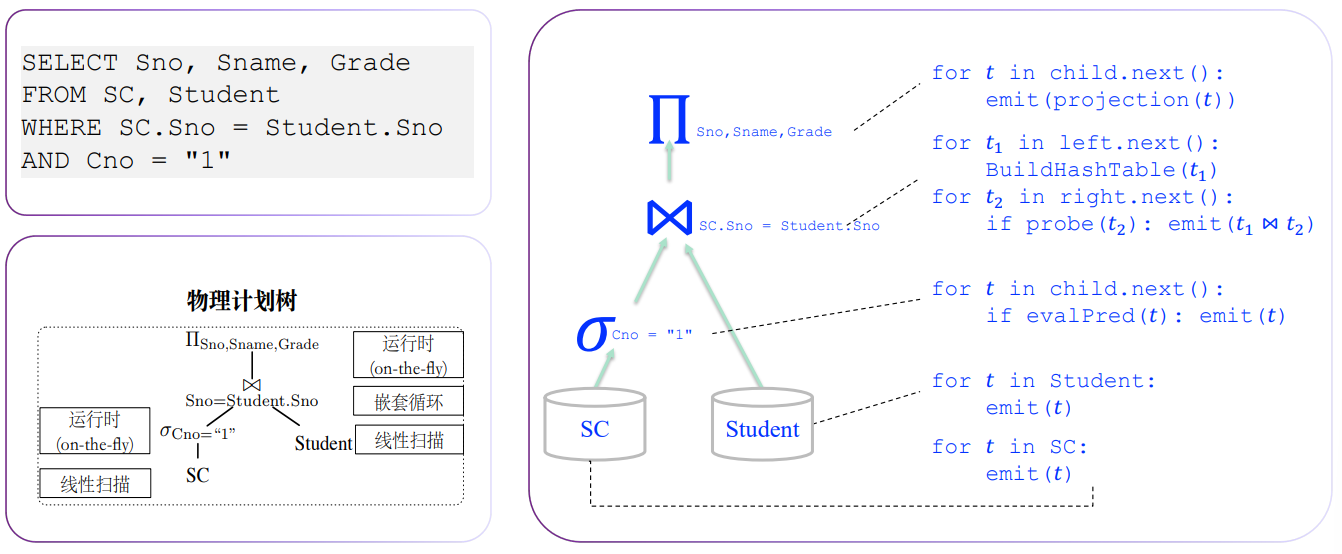
SQL解析
将SQL查询语句转换为等效的关系代数运算,且通常以基于关系代数的查询树来表示。
词法分析
- 通过自动机来提取关键字
- 按照查询语句的词法规则将查询语句拆解为单词(token)序列,并提取关键字、标识、常量等
- 标记单词类别,形成字符标记流
语法分析
将SQL语句变成一个语法分析树
- 根据词法分析的原子节点构建一颗语法分析树
- 按照语法规则判断SQL语句是否合法
- 识别出语法类节点,结合词法分析输出的原子节点构建出一棵语法分析树
语法分析树
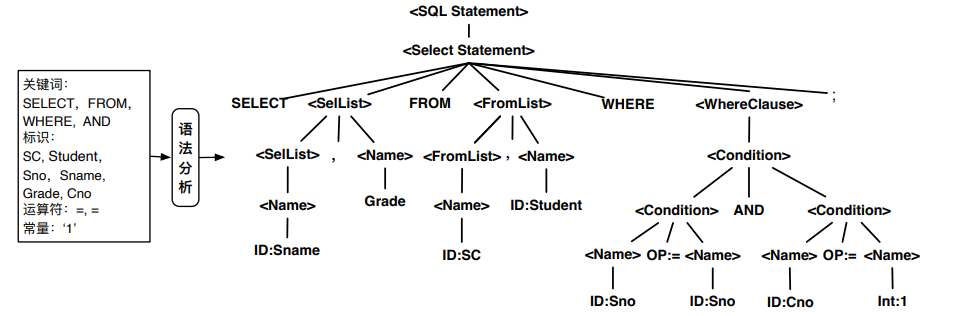
原子节点和语法类节点构成的一棵树,有原子节点和语法类节点
- 原子节点:指词法分析过程后被标记的单词;来源于词法分析,在语法分析树中作为 叶子节点出现,不存在后继节点。
- 语法类节点:上图中使用<名称>的形式来表示的节点
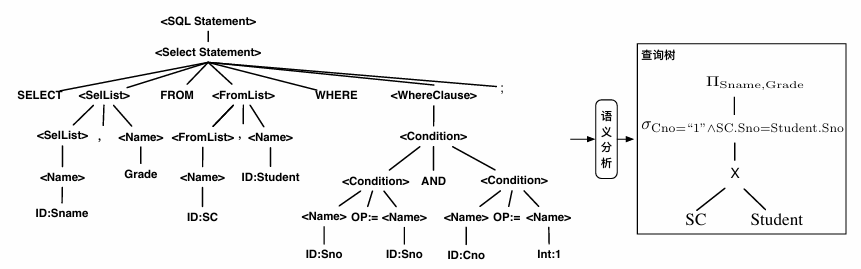
语义分析
语义分析要对语法分析所输出的语法分析树进行语义上的正确性检查,并将语法分析 树转化为方便查询优化阶段处理的查询树
正确性检查
- 对关系(表名)检查是否存在
- 对属性(列名)检查是否存在
- 对数据类型及其运算检查是否合法
查询树转化
转化为基于关系代数式表达的查询树便于优化
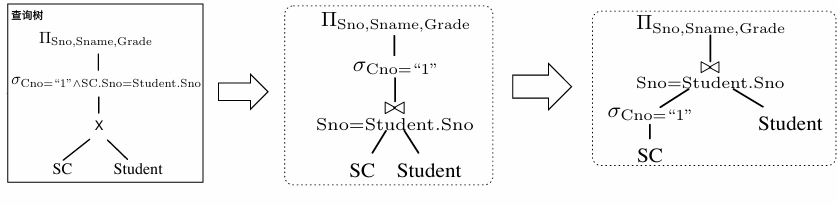
查询优化概述
逻辑优化
逻辑优化是找出与查询等价但执行效率更高的关系代数表达式,通过查询重写来提高效率。
给出逻辑执行计划
代价估计
将得到的逻辑执行计划转换为实际执行的物理计划过程
- 转化中确定实际实现方式:连接运算选择,连接顺序判断
- 通过代价估计模型(结果数)来估计不同物理执行计划的资源消耗
物理优化
物理层面的优化则是枚举各种物理执行计划,根据代价估计模型择出代价最小的物理执行计划
枚举不同的物理执行计划主要分为两方面:
- 选择逻辑算子的物理执行方式
- 枚举连接顺序,取优
从中选择出代价最小的物理执行计划提供给查询执行引擎执行
查询算子概述
算子就是不同工序中的不同执行者
在SQL执行过程中经历不同算子
查询算子
| 查询算子 | 实现方式 |
|---|---|
| 排序算子 | 内存排序、外部归并排序 |
| 选择算子 | 线性扫描、索引扫描 |
| 连接算子 | 嵌套循环连接、块嵌套循环连接、索引嵌套循环连接、排序归并连接、哈希连接 |
| 去重算子、聚集算子、集合算子 | 排序、哈希 |
磁盘I/O代价度量
磁盘I/O代价度量是指在查询处理中对计算资源的消耗,其中磁盘I/O占用是最主要的成本,尤其是在大型数据库系统中。查询的代价不仅涉及CPU时间,还包括数据的磁盘I/O操作,特别是分布式数据库时,还要考虑数据通信的代价。
在数据库系统中,磁盘I/O代价的度量常用磁盘I/O的块数作为指标。为了统一符号,常用以下表示方式:
- B® 表示关系 R 占用的磁盘块数
- T® 表示关系 R 中包含的元组数
- M 表示可用的内存缓冲块数
排序算子的实现与代价
当SQL查询中存在ORDER BY语句,该语句要求对结果中的元组进行排序,需要用到排序算子
主要的实现方式是外部归并排序
外部归并排序
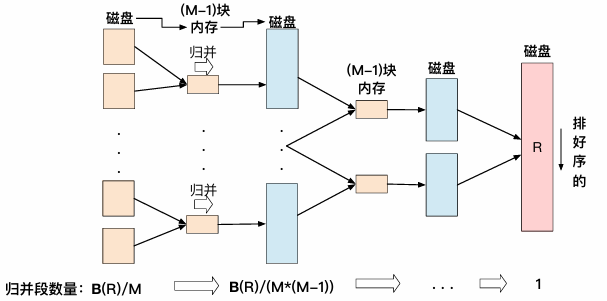
外部归并排序算法由两个阶段组成:排序阶段和归并阶段
- 排序阶段:首先划分多个归并段(run)
- 归并阶段:将已排序的归并段归并
代价分析
- 排序阶段:假设内存中可用的块数为M,因此初始归并段数为 ⌈B® / M⌉
- 归并阶段:初始归并段数为⌈B® / M⌉,每一次归并过程使归并段的数量减少到原来的 1/ (M−1).初始归并段数为⌈B® / M⌉,每一次归并过程使归并段的数量减少到原来的1/ (M−1),因此归并过程数为 ⌈log (B® / M)⌉
总结:
- 排序阶段需要将关系 R 的所有元组读入内存并写回磁盘,因此排序的总磁盘I/O代价为2B® ;
- 在归并阶段同样需要将所有元组读入内存并写回磁盘。因此每次归并阶段所需的磁盘I/O次数为2B®(共需要 ⌈log (B® / M)⌉次归并过程)
- 总代价:2(⌈log_(M-1) (B® / M)⌉ + 1) * B®
选择算子的实现与代价
实现选择运算最常见的算法是扫描整个关系并选出目标元组,有线性扫描与索引扫描两大类.
- 线性扫描:等值选择,范围选择
- 索引扫描:B+树聚簇索引,B+树非聚簇索引等值选择,范围选择
其中索引主要是指B+树索引,记ht为B+树的深度。
| 扫描算法 | 选择运算应用条件 | 运算代价 | 分析 |
|---|---|---|---|
| 线性扫描 | 等值选择 | B® | B® 个块的读取写,平均代价为B®/2 |
| 索引扫描 | B+树聚簇索引,等值 | ht + 1 | ht 次读取索引,读取数据一次(ht 索引高度) |
| 索引扫描 | B+树聚簇索引,等值 | ht + n | ht 次读取索引,读取 n 个满足条件的条数(不连续) |
| 线性扫描 | 范围选择 | B® | B® 个块的读取写 |
| 索引扫描 | B+树聚簇索引,范围 | ht + b | ht 次读取索引,读取 b 个满足条件的块数(连续) |
| 索引扫描 | B+树非聚簇索引,范围 | ht + n | ht 次读取索引,读取 n 个满足条件的条数(不连续) |
其它选择实现
合取选择(AND)
- 无索引:线性扫描
- 单列索引:根据该索引B+树查找算法检索出满足单个选择条件的所有元组,检查每个检索到的元组是否满足剩余的选择条件
- 多个单列索引:找出基数估计值最小的选择条件对应的列,根据索引检索出满足该选择条件的所有元组,检查检索到的元组是否满足剩余选择条件;或与其他列索引检索出的元组求交集
- 复合键索引:如果合取选择作用的多个列上建立有复合键索引,可以通过查找该复合键索引直接检索出满足选择条件的元组
析取选择(OR)
即多个选择条件用关键词“OR”连接的情况
- 无索引:线性扫描
- 所有要选择的列上都有索引:通过B+树查找算法分别检索出满足每个选择条件对应的元组集合,然后对这些集合应用集合,运算中的并操作来获得析取选择的结果
连接算子的实现与代价
关系连接是数据库中最常见且最耗时的运算之一
主要目标:等值连接(根据某列,将值相同的连接在一起)
嵌套循环连接
嵌套循环连接R⋈S算法伪代码:(R被称为外城关系,S被称为内层关系)
for r in R:
for s in S:
if (r,s) is true:
add(res, (r, s)) 代价:
- 由于关系R是分块读入内存,因此对于外层关系R的磁盘I/O次数为B®
- 最外层循环对关系R遍历,则外层循环的迭代次数为T®
- 对于每次遍历,需要按块将关系S读入内存,读入的内存块数为B(S)
- 对于内层关系S的磁盘I/O次数为T®⋅B(S)
- 总代价:B®+T®⋅B(S)
块嵌套循环连接
for BR in R
for BS in S
for r in BR
for s in BS
if (r,s) is true
add(res, (r,s)) - 由于关系R是分块读入内存,因此对于外层关系R的磁盘I/O次数为B®
- 最外层循环是对关系R中的每个块迭代,则外层循环的迭代次数为B®
- 对于每次外层循环的迭代,需要按块将关系S读入内存,读入的内存块数为B(S)
- 因此对于内层关系S的磁盘I/O次数为B®⋅B(S)
- 总代价:B®+B®⋅B(S)
优化的块嵌套循环连接
for BR_M-1 in R
for BS1 in S
for r in BR_M-1
for s in BS
if (r,s) is true
add(res, (r,s))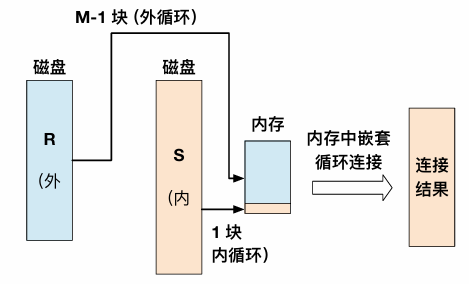
- 由于关系R是分块读入内存,因此对于外层关系R的磁盘I/O次数为B®
- 外层循环将关系R每次读M-1个磁盘块到内存,最外层的迭代次数为B®/(M-1)
- 对于最外层的每次迭代,会读取关系R的M-1个块和关系S的B(S)个块
- 总的磁盘I/O代价为B®+(B(S)⋅B®)/(M-1)
可以选择B®,B(S)较小的作为外层
- 总代价:Min(B®,B(S))+(B(S)⋅B®)/(M-1)
索引嵌套循环连接
当内层关系 S 的连接属性上存在索引,则可以将嵌套循环连接算法中的线性扫描用索引扫描来代替
即对于外层关系 R 中的每个元组r,可以利用关系S上的索引选择出满足连接条件的元组s,并将(r,s)放入结果中
- 读取关系 R 需要B®次磁盘I/O
- 对于关系 R 上的每个元组,在 S 中需要根据索引搜索出满足连接条件的元组,此部分的代价对应索引选择运算的实现代价
- 总代价:B®+T®·c(c是对于R的每条元组在S上根据连接条件进行选择的单次运算的平均代价)
排序归并连接
嵌套循环连接算法需要对所有可能的元组对进行筛选,这带来了很高的代价
- 排序:将需要连接的两个关系根据连接属性进行排序
- 连接:按照排序好的连接属性顺序分别扫描这两个关系,满足连接条件的元组将被组合成对
- 排序归并连接算法对每个关系中的元组只需扫描一次,即扫描 |R|+|S| 个元组
- 相比嵌套循环连接需要扫描 |R|⋅|S| 个元组相比大大减少了磁盘访问次数
- 但排序归并连接比嵌套循环连接多出了对两个关系进行排序的步骤
- 若已排好序,代价:B®+B(S)
哈希连接
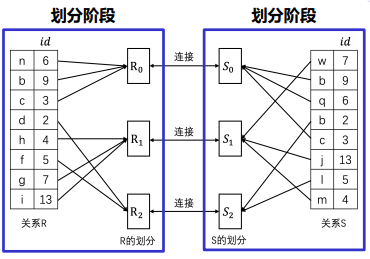
先划分后连接
- 使用哈希函数对关系R和S进行划分。
- 关系R和S被划分为K个桶:( R0, R1, …, R{K-1} ) ( S0, S_1, …, S{K-1} )
- 哈希函数将连接属性值相同的元组划分到同一个桶中。每对对应的桶 Ri 和 Si 进行连接。
- 共需K次迭代,每次迭代使用其他连接算法(如嵌套循环连接、排序归并连接或哈希连接)。
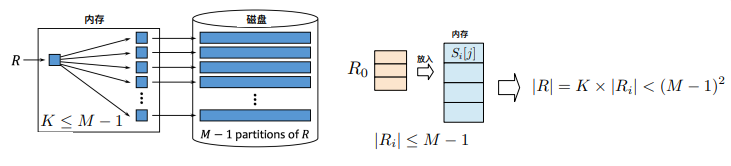
代价:
- 划分阶段的磁盘读取和写回,以及探查阶段的磁盘读取和写回
- 在划分阶段对两个关系 R,S 各需要一次读取和写回:2(B®+B(S))
- 探查阶段需要对每个关系划分读取一次,则需要B®+B(S)
- 总代价:3(B®+B(S))
约束:哈希桶数能放到内存,每个哈希桶也能放到内存(约束内存块数 M > sqrt(B®) + 1)
其他算子的实现与代价
其它算子依赖于排序和哈希划分来实现
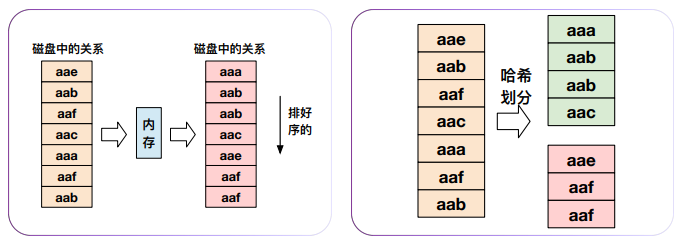
去重运算
基于排序或哈希划分实现:
在排序或哈希划分的过程中将重复的元组去除
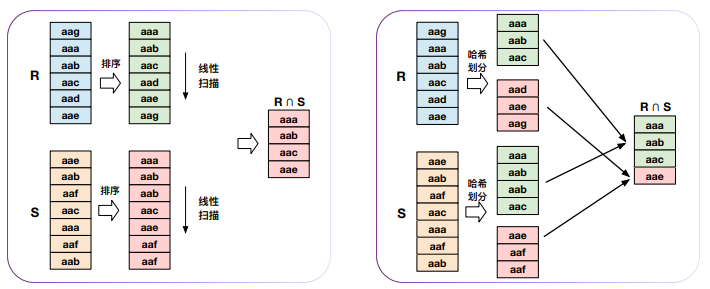
集合运算
集合运算可以基于排序或哈希划分实现
分组聚集运算
与去重运算的思路相同,可以使用排序或哈希划分实现关系的分组
与去重不同的是:去重是为了去除关系中重复的元组,而关系分组是将关系中相同的元组组合为一个组
