这篇文章上次修改于 526 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
索引概述
按照物理存储类型分类:
- 聚集索引:一张表只能有一个,按照key排序,范围查找更高效,
- 非聚集索引:一张表可以有多个,数据不一定按照索引列顺序存储。辅助索引、二级索引
按照指针记录的粒度分类:
- 稠密索引:索引指向记录
- 稀疏索引:索引指向页面
按照层数分类:
- 单级索引:只有一级,哈希
- 多级索引:索引上有索引,B+ Tree
按照字段特性分类:
- 主键索引:建立在主键字段上的索引,最多只有一个主键索引
- 唯一索引:建立在 UNIQUE 字段上的索引,可以多个,值唯一
- 普通索引:建立在普通字段上的索引
按照字段个数分类:
- 单列索引:建立在单个字段上的索引
- 多列索引:建立在多个字段上的索引
概念:
- 回表:在通过索引查找到相关记录之后,还需要再访问原始表来获取其他列的详细信息。索引只能帮助定位到一部分数据(如索引列),但如果查询需要返回其他列的数据,那么数据库系统会执行一次额外的查找操作(回表),从表中获取这些数据。
索引类型
- 点查询(score=90):哈希索引、B+树索引
- 范围查询(score>60):B+树索引
- 多列条件查询(gender=male & rating=5):位图索引
- 空间范围查询(115.7°<lag<117.4°& 39.4°<long<41.6°)最近邻查询(KNN):多维索引(R树、Quadtree、KD树)
B+树索引
索引结构
- 平衡多叉查找树:根到所有叶子节点路径长度相同
- 扇出:每个节点最多分叉数(通常200-300)
- 内部节点:索引页面号
- 叶子节点:数据记录页面号,数据记录槽号
- 可以将上面几层存于内存,提高IO效率。1亿数据只要4-5层
查找算法
点查询
- 从根节点逐层加载索引页面到缓冲区,直到叶子节点
- 注意只判断存在性时,也要访问到叶子节点
- 内部节点存在的键,叶子节点中不一定存在
区间查询
- 叶节点兄弟之间有指针
- 首先根据查找键查找左端点
- 然后按照节点指针向右线性扫描
插入算法
- 从根节点开始,找到适当的叶子节点。
- 直接插入叶子节点(如果空间足够)。
- 如果叶子节点已满,分裂成两个节点,并将中间值推送到父节点。
- 如果父节点已满,则进行递归分裂,直到根节点。
- 如果根节点分裂,树的高度增加,新的根节点包含两个子节点。
删除算法
- 从根节点开始,按照关键字的顺序查找,直到找到要删除的元素所在的叶子节点。删除后有两种情况:
- 键数 ≥ ⌈m / 2⌉ - 1 直接从叶子节点中删除该元素,删除完成。
- 键数 ≤ ⌈m / 2⌉ - 2 则需要进行合并或借用操作:
- 借用:从相邻的兄弟节点借一个元素来填补当前节点的空缺。借用的元素会从兄弟节点移到父节点中,父节点需要更新对应的指针和元素。
- 合并:如果相邻的兄弟节点借用不够,则将当前节点和兄弟节点合并成一个新节点,并将父节点中的指针和关键字也进行相应的更新。
- 父节点个数不够,下溢:递归处理父节点,直到根节点。如果根节点为空且没有其他子节点,则根节点将被删除,树的高度减少。
- 树的高度变化:如果根节点发生变化(比如被删除),树的高度会减少,新的根节点会是合并后的子节点。
B+树并发控制
查找操作(读操作)可以并行进行
读(查找)写(插入)同时进行,则可能发生错误:读写不一致、节点分裂找不到数据
闩锁耦合
主要的并发控制出现在修改了B+树的情况。
自顶向下加锁:
- 读操作:加共享S(闩)锁
- 写操作:加互斥X(闩)锁
节点安全,释放其祖先节点的锁:
- 节点安全:该节点及以上结构不会因此操作发生变化
- 插入操作时:未满的节点是安全的;溢出不安全
- 删除操作时:多于半满的节点是安全的;下溢(少于半满)不安全
- 查找操作时:不会改变结构,一定是安全节点
如果A节点下面有B节点,先访问A节点,给A节点加锁,通过访问到B节点是否安全来看A节点是否可以解锁。一旦子节点安全,上面的锁就可以都释放。
读者-写者模型:
- 读者之间可以并发访问
- 在没有读者时写者才能访问
- 写者之间互斥
缺点:
- 闩锁耦合自上向下加锁,锁竞争严重,特别上层节点访问频繁
- 有可能发生要给整个树都读写加锁导致堵塞
自下而上的乐观锁
- 读操作:与闩锁耦合一致(自上而下加读锁)
- 写操作:自上而下加读锁,找到叶节点
- 插入:尝试对叶子结点升级写锁,叶子节点不满,直接插入,满了就对父节点加写锁,以此类推。如果中途不可加写锁,使用闩锁耦合方案从上而下重试
- 删除:尝试对叶子结点升级写锁,大于m/2孩子,直接删除,下溢就对父节点加写锁,以此类推。如果中途不可加写锁,使用闩锁耦合方案从上而下重试
B-link树
- 当节点A溢出[min,max):锁定该节点
- 通过中间键拆分 a’:[min,k) b:[k,max)
- a’ 赋值给 a :
- 如果此时查找[min,k) 之间的值,依旧不影响
- 如果此时查找[k,max) 之间的值:加一个从a’到b的link,通过指针到b找该查找键
如何判断查找键不存在?还是存在于右兄弟节点?
- 每个节点加一个high-key,即本节点的最大键值
- 如果查找键 > high-key:则到右兄弟节点查找
- 如果查找键 ≤ high-key:则在本节点查找
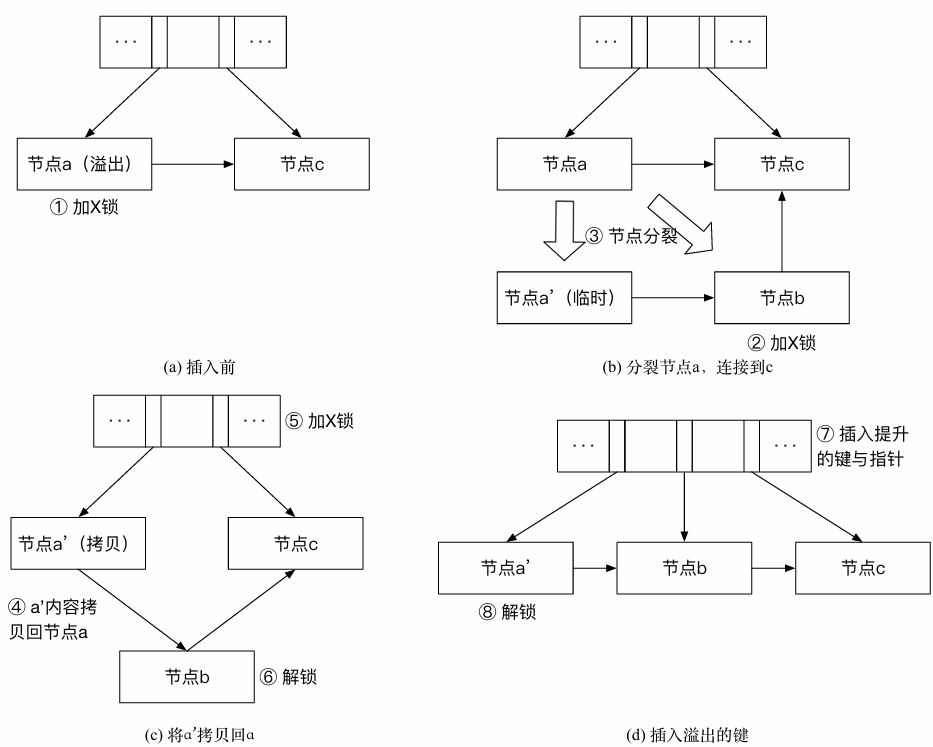
思想
- 将k移动到a’和b的父亲节点
- k的左指针指向a,右指向b,插入结束,解锁。
- 最多锁三个节点:a‘,b,父亲节点
- 内部节点也有兄弟指针,节点分裂的中间状态也为合法状态
B-link树仍然存在锁竞争
Bw树
将更新作为一个单元,多次更新相当于单元进行链接成链表,读取页面的时候,把修改的行为一同读取,到后来的时候应用修改即可。
特性
- Bw树为无锁结构,避免锁竞争
- 使用CAS原子操作使更新生效
- 页面不可修改(LSM-tree思想合并更新)
- 页面原位更新 → 增量更新页面(适合SSD/Flash)
结构
将页面逻辑ID映射到内存或硬盘的物理页面地址
- 原页面𝑃的物理地址
- 页面逻辑ID当前映射的物理地址
- 以及增量记录Δ𝐷的物理地址
- CAS指令或者保留逻辑页面ID当前指向的物理地址,或者更新为Δ𝐷。
行为
- 页面映射表将逻辑页面ID映射到链表第一个节点
- 页面分裂:类B-link, 对插入节点与父节点页面更新
哈希索引
静态哈希表
桶数固定
闭哈希
当哈希值插入的位置已经有其他元素:( i 是冲突次数)
- 线性探测:下一个位置 + i (容易堆积)
- 平方探测:下一个位置 + i * i
开哈希
当插入哈希值满时,新建哈希桶,通过哈希桶链表链接(拉链法)
可扩展哈希表(动态哈希)
带有二进制位数的桶指针。
结构
只考虑两层:
- 全局目录层:保存指向桶的指针。全局目录大小由哈希函数和桶的数量决定,通常是固定大小,但会根据数据量的变化而扩展或缩减。
- 桶层:实际存储数据记录的地方。每个桶对应某些哈希值范围的数据。当一个桶满了,可能会发生分裂,将部分数据迁移到新桶,并相应更新全局目录。
概念解释:
- 全局深度:全局深度是指全局目录中指针的位数。它决定了全局目录的大小(2^全局深度个指针)。全局深度反映了哈希表的“全局”层次。
- 本地深度:本地深度是每个桶的深度,它表示该桶在全局深度的基础上使用的哈希位数。每个桶都有自己的本地深度,决定了它使用全局哈希值的前几位进行分配。
特性:
- 对于一个bucket来说,如果当前的global depth等于local depth,那说明这个bucket只有一个指针指向它。
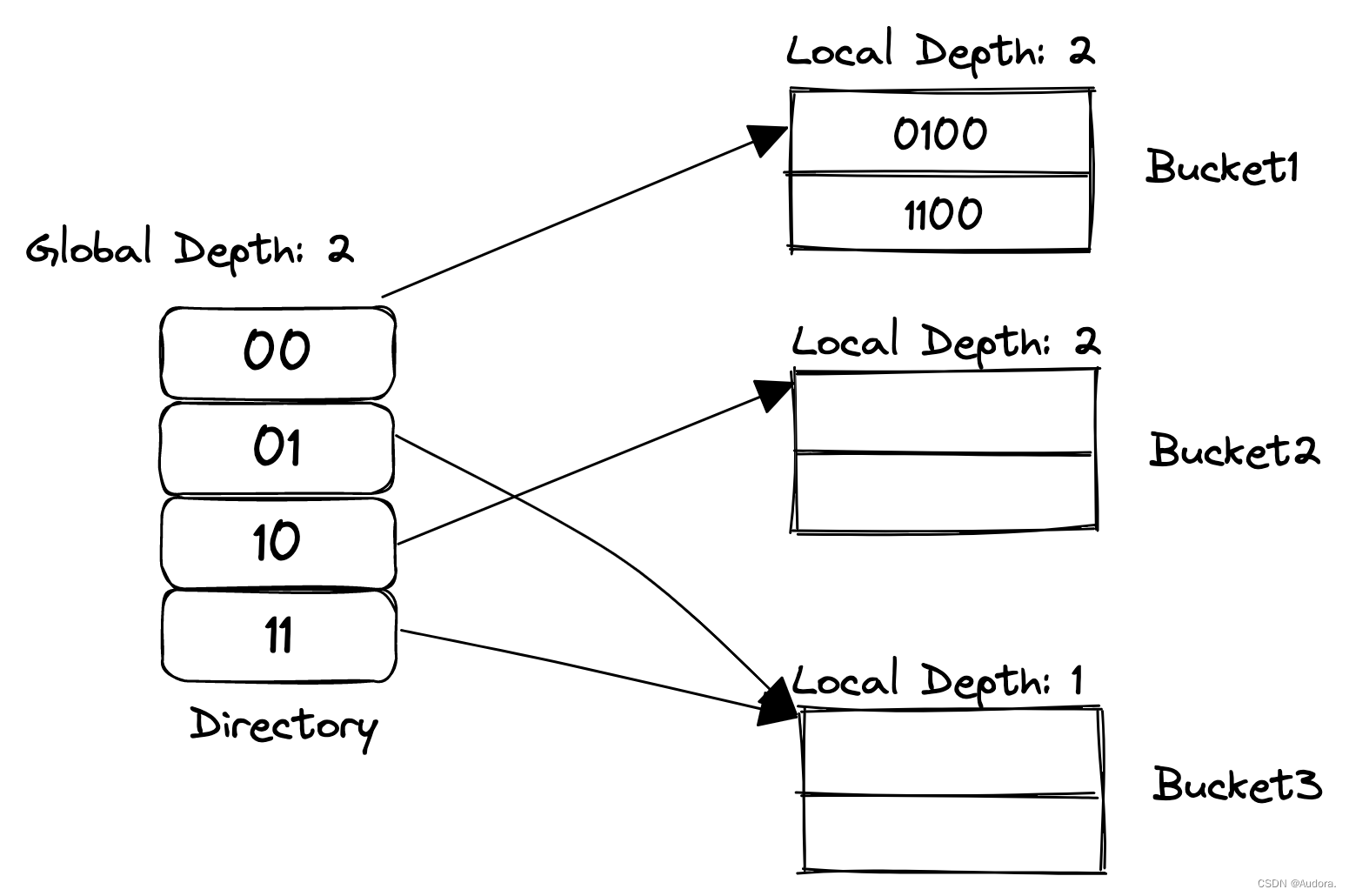
设全局深度为A,本地深度为B
查找键值K时
- 例如我要查找key,先获取key的低A位,通过低A位对应的目录找到对应的桶。桶内有满足目录的key,但不是都满足目录key。
- 在桶内,使用一个合适的查找方法(如线性查找或二分查找)来确认是否存在键值 k。如果桶内存在 k,则返回对应的值。
插入键值K时
初始的时候,全局深度和本地深度都为0。所以一开始的数据都会直接放入唯一的桶,因为所有数的低0位都是空。
- 先找到插入的桶,如果桶没满,则插入桶。
- 如果桶满了
- global depth > local depth:将满的桶进行分裂,增加两个桶的本地深度(B),取出原来满了的元素,按照新的低B(原来的B + 1)位进行分配。
- global depth = local depth:要将全局深度+1,也就是拷贝一遍目录层,直接将目录的数量翻倍,指针还是指向原来的位置。
删除键值k时候
- 初始时,根据哈希值找到包含键值 K 的桶。
- 删除 K 后,检查桶是否为空:
- 如果桶为空,考虑合并。
- 合并操作:如果桶本地深度等于全局深度,则可以进行合并,合并后的桶的本地深度减小。合并后,可能需要更新目录,并根据情况减少全局深度。
- 更新目录:合并操作后,如果需要,缩小目录,减少全局深度,删除不再指向有效桶的指针。
缺点
- 哈希表每次容量加倍时需要阻塞对整个哈希表的访问,降低了系统性能
- 如果少量桶多次溢出,则需要频繁对哈希表进行扩容,造成一部分桶空,导致空间浪费(例如所有元组哈希值前n位都相同)
线性哈希表
- 允许在页面后链接存放溢出数据的页面,更加节省空间
- 能够实现在哈希表扩容时仅需要对个别桶进行分裂,不会大规模阻塞对哈希表的访问。
结构
- 目录层:目录层存储指向桶的指针,用于决定数据应存储在哪个桶中,初始时只有一个指向第一个桶的指针,目录深度为1。
- 桶层:桶层存储实际的数据项,每个桶用来存放哈希值对应的元素,初始时只有一个桶用于存储数据。
设目录层的目录数为n,现在的目录数不一定是2的整数幂次。设目录深度为m,也就是查找目录的时候通过后m位取值。
查找键值K时
哈希值后 𝑚 位取值范围为0~2^𝑚 −1,通过后m位找到对应目录指向的桶。
- 后m位的值为x,通过x在目录层查找对应的目录
- x < n,代表存在这个目录,在目录指向的桶内查找。
- x ≥ n,代表不存在这个目录,查找减去一位的桶,也就是后m - 1位值对应的桶。
插入键值K时
插入数据时的过程会根据当前哈希表的填充率决定是否需要分裂桶或新增溢出桶。
- 填充率: 当前的桶数 * 每个桶的存储数据量 / 目录数
当哈希表的填充率 ≤τ 时:
- 如果某个桶已满,使用溢出桶(通过链表连接),新数据插入溢出桶,不增加桶的数量。
当哈希表的填充率 > τ 时:
- 执行桶分裂,将现有桶分裂为两个新桶。
- 新桶的哈希值为当前桶数 ,并将桶数增加 1(n = n + 1)。
- 根据哈希值,重新分配数据到新的桶。
一致性哈希
对于一个普通的hash算法,如果容量size发生变化,那么所有的数据都需要重新hash。
一致性hash保持了状态,减少了大的开销。
结构
- 将哈希值组织成为一个环[0,max)
- 在哈希环上选择k个值作为数据分片
- 哈希值在[hi-1,hi)之间的数据放在Di分片,哈希值在 [hk, max), [0, h1)之间的数据放在D1分片。
添加一个数据分片
- 添加一个哈希值hx,假设h2<hx<h3
- 添加一个数据分片Dx
- 将D3中的一部分数据,满足[h2,hx)移到Dx
删除一个分片
- 假设删除数据分片Di
- 将Di中的数据移到Di+1
特点
- 删除和添加只会影响一个分片失效,不会影响整个失效。
hash偏斜
问题:某些数据分片数据较多,某些数据分片数据较少,分布不均匀。
增加虚拟节点,虚拟节点对应哈希环上的值,物理节点包含多个虚拟节点。
SkipList跳表索引
是一种用于实现快速查找、插入和删除操作的数据结构,尤其适用于在有序列表中进行高效查找。它是由 William Pugh 在 1989 年提出的,作为平衡二叉树的一种替代方案,具有简单、易实现的特点。跳表通过多层次的链表结构来提高查找效率,能够在平均情况下实现O(logn)的时间复杂度。
结构
- 底层链表:跳表的最底层是一个有序链表,包含所有的元素。这个链表与普通的链表类似,通过节点的指针进行连接。
- 上层链表:跳表的上层是对下层的一个索引,每一层只包含部分元素,按照一定的规则进行筛选。层数越高,节点数量越少。每个节点不仅包含指向后一个节点的指针,还包含一个指向下层节点的指针。
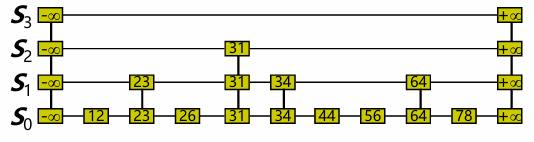
查找
- 从最上层开始查找,对于每个位置p, 比较 x 和 next(p) 的大小
- x = next(p) 返回对应元素
- x > next(p) 本层向前扫描
- x < next(p) 跳转到下一层
- 如果到最底层还没找到,则返回空
插入
- 通过抛硬币的随机过程(硬币连续抛出正面的次数 i ),确定插入节点的层数 i 。
- 根据层数决定是否需要新增层(如果 i 大于当前最大层数)。
- 从最高层到最低层依次进行查找,找到合适的位置。
- 在每一层中插入节点,确保每一层都是有序的。
删除
- 删除在每一层中链表的节点。
- 如果有多个正无穷到负无穷的链表,保留最底层的。
LSM树索引
B+树在更新密集的场景产生大量随机I/O
LSM树将更新操作转化为批量顺序写入
思路:多级索引积累更新后进行索引合并
2阶LSM树
冷热分离,将更新的部分索引树更新在热层,也就是内存,当内存中的更新索引到达一定量,将索引更新写入日志,再将整个热层的索引更新到磁盘层。
结构
- 内存索引C0(热层):通常使用红黑树、AVL树。缓存区中缓存C1、进行滚动合并,WAL持久化C0更新。
- 外存索引C1(冷层):通常使用B+树。
索引查找时
- 先在C0中进行查找,存在则返回
- 否则在C1中进行查找
滚动合并
当C0的树容量到达了一定大小,需要更新到C1上,此时就进行滚动合并。
步骤:
- 空置块中加载C1树叶子节点的连续页面
- 填充块中从C0树中取出节点,与空置块进行合并
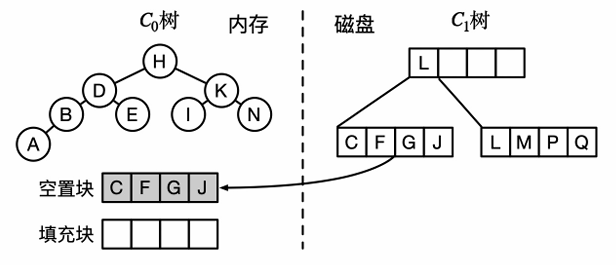
- C1树参与合并的节点被标记移除
- 空置块中来自C1树的剩余的数据随着C0树继续合并被消耗
- 填充块满后追加到C1树文件末尾:C1树结构变化也通过延迟删除、追加更新的方式实现
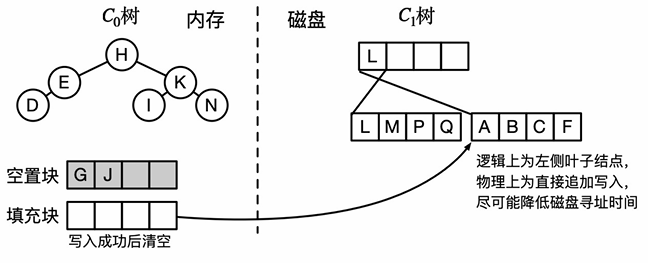
索引删除与更新
- 索引删除:在C0中查找删除的条目,若待删除条目存在,则直接从C0中删除;否则在C0中插入删除条目(合并入C1时进行删除)
- 索引更新:(视作删除旧条目,插入新条目)
多阶LSM树
为降低相邻层级的滚动合并参数,引入磁盘上的多级索引
相邻层级容量比例固定时,LSM树I/O成本最低
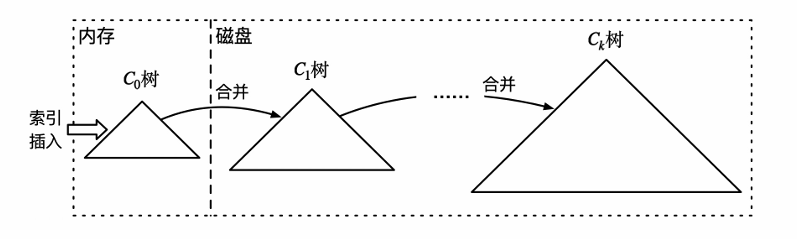
操作
- 插入:先插入内存,如果内存满刷新到第一层,第一层满和第二层合并,以此类推
- 查找:先查找内存,如果找到返回,否则逐层往下找
- 删除:在内存中标记删除
- 合并:异步合并删除
LSM树优化
滚动合并实现复杂,增加简化条件:
- 内存部分:采用B+树、skiplist等并发安全索引
- 磁盘部分:各层只允许通过合并生成新索引与删除,禁止修改
LSM树性能问题
- 读放大(布隆过滤器优化):查找时若未命中,则需逐层索引查询,增加了I/O
- 写放大(分区优化):合并时需要在内存中完成,不断读入、归并、写回
- 空间放大(异步压缩机制,物理删除被标记删除的数据):键值可能存在于多层中
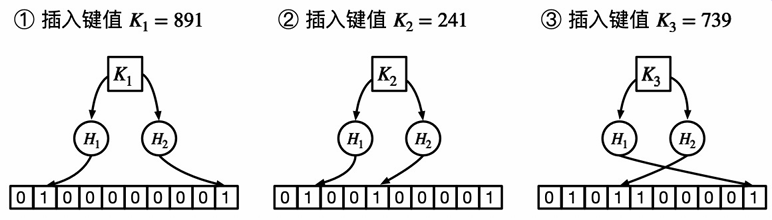
布隆过滤器
目的:高效检测键值在集合中的存在性
结构:m比特的0/1数组arr,k个哈希函数
插入示例(m = 10 k = 2 的布隆过滤器):
检验示例
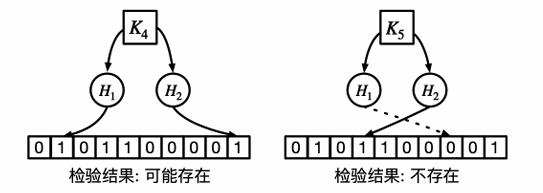
通过假阳率分析来判断是否可能存在
分区优化
- 索引合并的内存与时间开销大
- 将大容量索引拆分成小分区
- 优化针对两种情景:
- 分区无重叠:合并范围不重合时,可以直接追加新分区
- 偏斜更新:避免无用分区,优化分区的均衡
LevelDB实例
位图索引
结构
位图索引通过为每个可能的列值创建一个位图(bitmap),在位图中,每一位代表表中某一行的数据是否符合该列的某个特定值。对于每个不同的列值(例如,性别字段的“男”和“女”),都会生成一个位图,位图中的每一位对应于数据表中的一行。如果该行的数据在该列上等于该列值,则相应位置的位是1,否则是0。
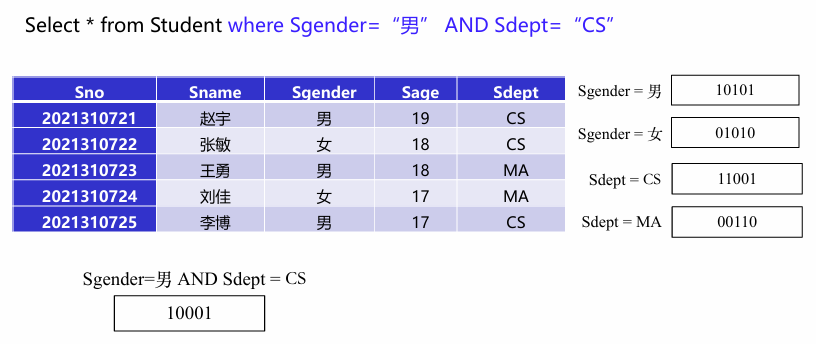
预先构建位图索引
- 列的取值种类较少时适用
查询执行中进行动态构建
- 根据列上的B+树索引/哈希索引得到满足条件数据的位图
- 位图索引扫描(bitmap index scan
多维索引
网格文件
将整个空间划分为网格,可视作多维的哈希表,每个网格为一个桶。
最近邻查询:先在给定点落在的网格内查找,再到临近网格查找
范围查询:找到与范围有交集的网格
四叉树
网格文件网格静态划分后难以调整
K维数据的四叉树,每层将子空间等分为 2k 份
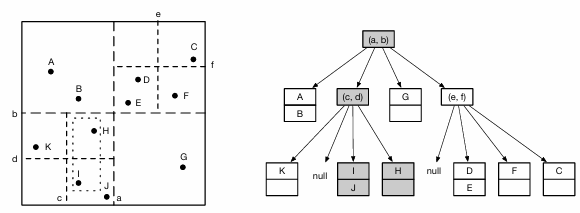
KD树
四叉树对于分布稀疏的数据会有大量空节点
KD树每层对一个维度进行分割:针对数据点进行二分,避免了大量空节点
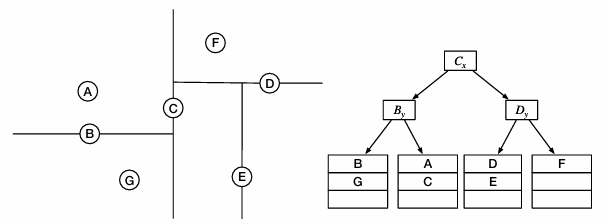
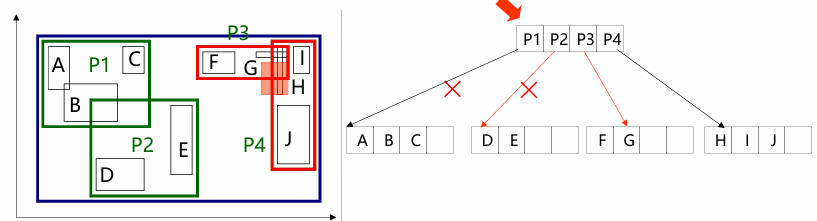
R树
空间数据的B+树,物体用最小外接矩形表示
节点分裂(启发式方法):贪心,使缩减面积最大
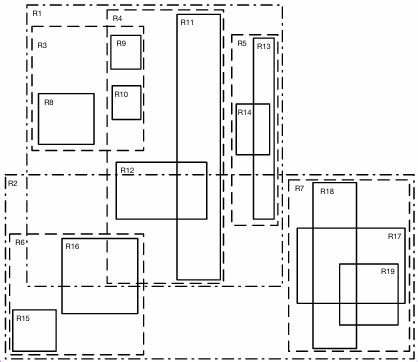
点查、范围
从上往下遍历,跳过不相交的节点