这篇文章上次修改于 470 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
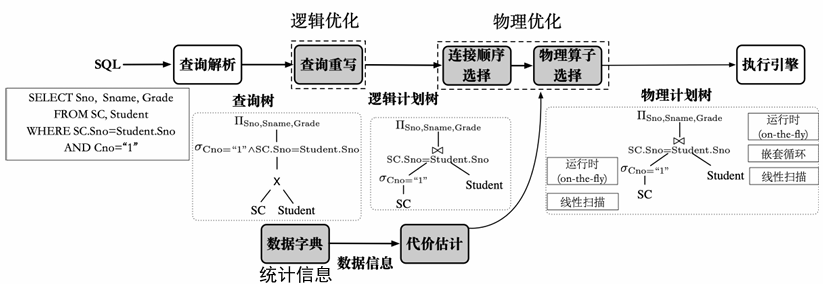
逻辑优化(查询重写)
- 查询重写:按照等价规则对关系代数表达式进行等价转换,提高效率
- 等价:对于两个关系代数表达式,等价替换后总能得到相同结果,则等价
查询重写规则
笛卡尔积,并,交,连接,都符合交换律和结合律
查询重写策略
-
①分解复合选择谓词。例如:𝜎 p1⋀p2 ® = 𝜎p1( 𝜎p2® ) 可以提前略去一些,减少判断
-
添加推理谓词。例如:A=B,A>5 → B > 5 确保优化周到
-
②下推选择运算。例如:𝜎p(R1⋈ R2) = 𝜎p(R1) ⋈ R2 可以对中间关系的大小进行缩减,减少运算次数
-
③笛卡尔积转为连接运算。例如:𝜎p(R1 × R2) = R1 ⋈p R2
-
④引入并下推投影。例如:ΠS1 (ΠS2 ®) = ΠS1 ®,S1 ⊆ S2,减少中间结果列的数量,降低中间结果的数据规模

其他重写策略:子查询转为连接
SELECT Sno, Sname, Sdept
FROM Student
WHERE Sno IN
(SELECT Sno
FROM SC
WHERE Cno="1");优化为
SELECT Student.Sno,Sname,Sdept
FROM Student, SC
WHERE Student.Sno=SC.Sno AND Cno="1";其他重写策略:常数传播
SELECT SC.Sno, Student.Sname, SC.Grade
FROM Student, SC
WHERE Student.Sno=SC.Sno AND Student.Sno<100;优化为
SELECT SC.Sno, Student.Sname, SC.Grade
FROM Student, SC
WHERE Student.Sno=SC.Sno AND Student.Sno<100 AND SC.Sno<100;其他重写策略:去除非必要谓词
SELECT MAX(DISTINCT Grade)
FROM SC
WHERE Cno="1";优化为
SELECT MAX(Grade)
FROM SC
WHERE Cno="1";物理优化
对于查询重写后,要需要完成
- 符合交换律和结合律的运算的执行顺序
- 逻辑计划中每个算子在物理执行时采用的算法
- 逻辑计划中未体现出的物理运算,例如排序和扫描
- 在运算符之间数据传递的方式
故使用代价模型来确定计划优劣
代价估计
代价估计的核心是基数估计,有以下概念(p为谓词)
- 基数:查询结果的元组数。表示为 card(p)
- 选择度:符合𝑝元组占所有元组的比例,表示为sel(p)
统计信息说明:
| 符号 | 说明 |
|---|---|
| T® | 关系R的元组数目 |
| B® | 关系R的所有元组需要的页面数 |
| L® | 关系R一个元组平均所需的字节数 |
| f® | 一个页面能存储的关系R的元组数 |
| min(R,A) | 关系R在属性A上取值的最小值 |
| max(R,A) | 关系R在属性A上取值的最大值 |
| V(R,A) | 关系R在属性A上不同值个数。当A扩展为属性集合a时,V(R,a)表示关系R在属性集a上投影后不同的元组数,即Πa®元组数 |
| MCV(R,A) | 关系R在属性A上取值最频繁的topk(most common value) |
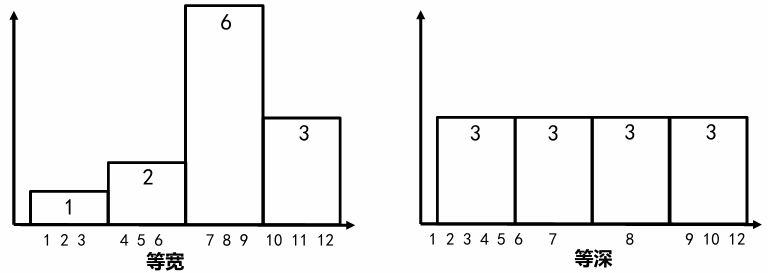
估计工具:直方图
等深直方图(equal-depthhistogram):按属性不同值出现频率调整区间宽度
等宽直方图(equal-width histogram):将属性按照相同间距划分区间
选择运算的基数估计
等值谓词
- 形式:𝜎 A=x ®
- 估计:T® / V(R, A)
范围谓词
- 形式:𝜎 A≤x ®
- 估计规则:
- 若 x < min(R,A):0
- 若 x ≥ max(R,A):T®
- 若在区间内:
- 其他运算符类推
连接运算的基数估计
考虑两个关系 R1(A, B) 和 R2(A, C)
属性 A 为这两个关系进行自然连接的属性集合,B 和 C 分别是关系 R1 和 R2 的非连接属性。
要进行结果基数估计的自然连接是 R1(A, B) ⋈ R2(A, C) 。
基数估计结果为:
连接顺序选择
- 连接树:表示n个关系连接时采用的连接顺序,是一个二叉树,只有叶子节点是关系模型,内节点都是连接运算。
- 左深连接树:内部节点的右子节点都是叶子节点的连接树
- 右深连接树:内部节点的左子节点都是叶子节点的连接树
- 浓密树:不是左深树和右深树的连接树
n个关系构成的结构不同的连接树个数为卡特兰数。全排列一定对应一个连接树。
我们仅考虑左深连接树,因其数量小,利于连接运算高效运行。
动态规划算法
对于枚举所有的左深连接树,我们可以将子问题存储,提高子问题的利用率。
若要连接[R1, R2, R3, R4 … Rn] 所有关系
当枚举到任意子集 S 例如 [Ra, Rb, Rc, Rd],可被拆为S1和S2,记
- C(S):为 S 所有连接中最小的代价
- ConCost(S1, S2):连接子集S1和S2的连接代价,估为T(S)
- C(S) = C(S1) + C(S2) + ConCost(S1, S2)
我们需要枚举所有子集,使用动态规划即先遍历所有大小为1的子集,再递增上去。
对于任意子集,有 C(S) = ( C(S), C(S1) + C(S2) + ConCost(S1, S2) ),其中S1 S2之间的分界线随枚举而定。
空间复杂度O(2^n) 时间复杂度 O(n * 2^n),稠密树时间复杂度 O(3^n)
以下是一个例子,R1 —A— R2 —B— R3 —C— R4,仅结果练习验证,过程略
第一轮:
| 关系集合 S | T(S) | V(S, A) | V(S, B) | V(S, C) | C(S) | Seq(S) |
|---|---|---|---|---|---|---|
| {R1} | 1000 | 50 | - | - | 1000 | R1 |
| {R2} | 1000 | 40 | 100 | - | 1000 | R2 |
| {R3} | 1000 | - | 20 | 200 | 1000 | R3 |
| {R4} | 1000 | - | 1000 | 1000 | R4 |
第二轮:
| 关系集合 S | T(S) | V(S, A) | V(S, B) | V(S, C) | C(S) | Seq(S) |
|---|---|---|---|---|---|---|
| {R1, R2} | 20000 | 40 | 100 | - | 22000 | R1⋈R2 |
| {R2, R3} | 10000 | 40 | 20 | 200 | 12000 | R2⋈R3 |
| {R3, R4} | 4000 | - | 20 | 200 | 6000 | R3⋈R4 |
第三轮:
| 关系集合 S | T(S) | V(S, A) | V(S, B) | V(S, C) | C(S) | Seq(S) |
|---|---|---|---|---|---|---|
| {R1, R2, R3} | 200000 | 40 | 20 | 200 | 213000 | (R2 ⋈ R3) ⋈ R1 |
| {R2, R3, R4} | 40000 | 40 | 20 | 200 | 47000 | (R3 ⋈ R4) ⋈ R2 |
第四轮:
Seq{R2,R3,R4} ⋈ Seq({R1}) 代价:848000
Seq{R1,R2} ⋈Seq({R3,R4}) 代价:828000
选择Seq{R1,R2} ⋈Seq({R3,R4}) : (R1 ⋈ R2) ⋈ (R3 ⋈ R4)
贪心算法
每次选择当前状态下增加的代价最小的关系连接。
步骤:
- 选择一个大小T® 最小的关系作为当前Rcur
- 从余下没有被选择过的关系中选择与Rcur连接后结果最小的Rnext,将Rcur更新为Rcur ⋈Rnext
- 不断重复步骤2,直到所有关系都被选择过。
时间复杂度(n2)
以下是一个例子,R1 —A— R2 —B— R3 —C— R4
| 关系集合 S | T(S) | V(S, A) | V(S, B) | V(S, C) |
|---|---|---|---|---|
| {R1} | 1000 | 50 | - | - |
| {R2} | 1000 | 40 | 100 | - |
| {R3} | 1000 | - | 20 | 200 |
| {R4} | 1000 | - | 1000 |
由于R2可以和R1和R3连接,故选取R2作为Rcur
比较 R1⋈ R2 和 R3 ⋈ R2 的代价
| 关系集合 S | T(S) | V(S, A) | V(S, B) | V(S, C) |
|---|---|---|---|---|
| {R1, R2} | 20000 | 40 | 100 | - |
| {R2, R3} | 10000 | 40 | 20 | 200 |
由于T(R2 ⋈ R3) 更小,选择 Rcur = R2 ⋈ R3,尝试连接R1或者R4
| 关系集合 S | T(S) | V(S, A) | V(S, B) | V(S, C) |
|---|---|---|---|---|
| {R1, R2, R3} | 200000 | 40 | 20 | 200 |
| {R2, R3, R4} | 40000 | 40 | 20 | 200 |
T((R2 ⋈ R3) ⋈ R1) 和 T((R2 ⋈ R3) ⋈ R4),T((R2 ⋈ R3) ⋈ R4)更小,选择Rcur = (R2 ⋈ R3) ⋈ R4。
仅剩下R1,故选择R1,有((R2 ⋈ R3) ⋈ R4) ⋈ R1 作为最终结果。
由于贪心并不会考虑周全,故该方案只是较优,并非最优
遗传算法
启发式的优化方法,从多个不同的连接顺序中不断进行优化和淘汰。
作为随机化算法,优化结果具有不确定性。
概念:
- 交叉:对连接顺序进行组合替换。也就是由已有的两个连接顺序合并为一个新的连接顺序,其中每个连接顺序只有一部分被保留在合并后的结果中
- 变异:对某个顺序自身进行调整(例如替换物理算子),得到一个新的连接顺序
- 选择:代价较低的顺序,直接遗传到下一代
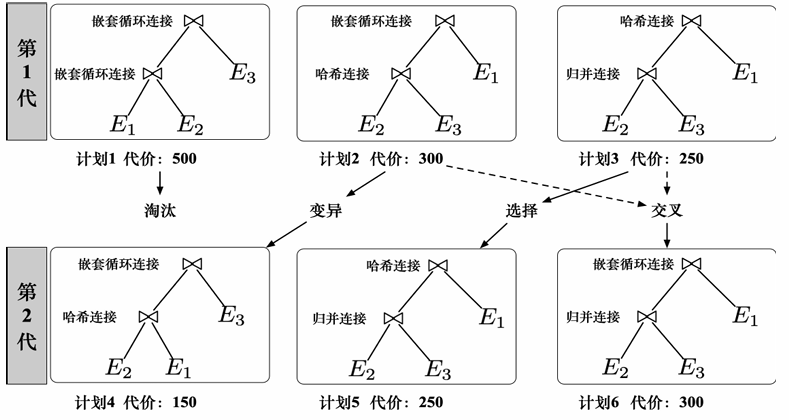
步骤:
- 初始化:随机选择一批计划
- 第一轮:计划1代价最大,被淘汰
- 计划2、计划3 变异,选择与交叉,得到第二轮候选计划
- 不断迭代以上过程,结束条件:代价不再降低;达到轮数
物理算子选择
添加每个算子的物理算子代价,动态规划中添加物理算子代价。
将动态规划多考虑一维,来表示不同算子作为连接的代价。
Selinger风格的优化
对于每个子表达式不只保留代价最小的计划,也会保留一些当前代价较高,但具有一些可能利于后续优化的性质的计划。
有趣顺序:Selinger风格的优化器考虑的性质是查询计划的输出结果在某列的有序性。(查询可能要求有序或者大幅度降低后续运算的代价)
(动态规划算法中单独保留带有顺序方法的计划即可)
优化器系统
优化器系统的计划生成
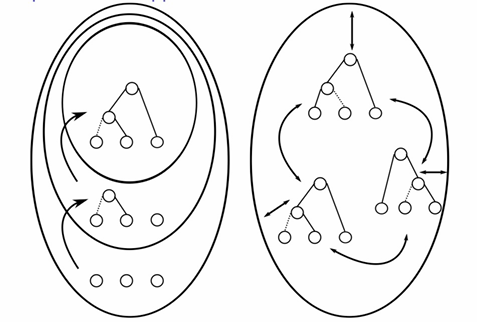
自底向上(R系统)
- 直观,易于实现,但是难以使用剪枝策略,无法提前停止。
- 枚举计划并选择代价最低的计划
动态规划是一种典型的“自底向上”的方法,由上图可以看出,左边的就属于自底而上,和上面使用动态规划的思路一致,从小的子集计划到大的计划。
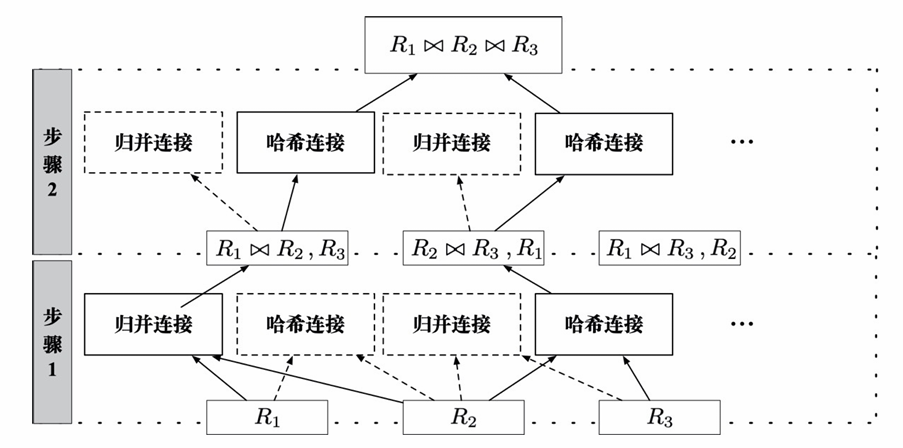
- 容易实现,不需要穷尽搜索就能找到较为合理的执行计划
- 仍然没有摆脱启发式转换,优化时间长,添加规则繁琐
自顶向下(Cascades)
- 实现比较复杂,但易于添加新规则,可以进行大量剪枝
- 优化的过程中不断剪枝
以查询的最终输出为起点,由计划树的根节点向下进行搜索,不断添加为得到最终输出需要的逻辑算子和物理算子,最终确定要采用的计划树
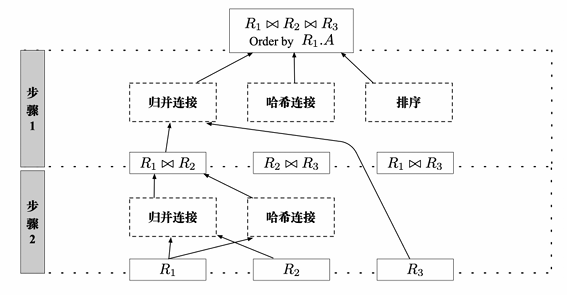
- 相较于两阶段的方法,统一搜索会产生更多的转换,优化效果可能更好,可以提前中止,添加规则简单
- 空间开销更大、优化慢、添加规则繁琐
优化器系统的发展
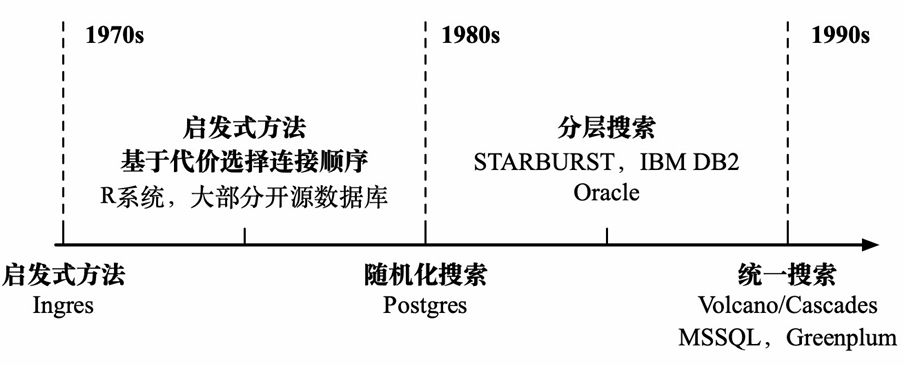
启发式方法
通过在优化器代码中静态定义规则来实现由逻辑计划到物理计划的转换
- 优先执行选择度更高的选择运算
- 在连接运算前执行所有的选择运算
- 当选择条件为等值时,如果关系在该属性上有索引,则优先使用索引扫描
优点:易于实现与调试;优化速度快
缺点:完全依赖于预定义的规则;复杂查询优化效果不好,没有考虑算子之间的相互关系
启发式方法+代价选择连接顺序
利用静态规则进行初步优化(有 R系统,早期的IBM DB2等等)
利用动态规划算法选择多表连接时的连接顺序(首次基于代价+自底而上)
优点:通常无需进行穷尽的搜索就可以找到一个比较好的计划,简单易实现
缺点:添加规则繁琐,优化时间慢,左深连接树不总是最优,在代价模型中需要考虑到数据的物理属性(例如有序性)
随机化搜索
(Postgres中的遗传算法。仍在Postgres中进行应用)
利用随机化策略来跳出搜索空间中的局部最优
优点:可以快速优化各种复杂查询,内存占用较小,计划质量好于启发式,优化速度好于动态规划
缺点:计划质量无法保证,无法在所有情形下都得到好的优化效果
分层 + 统一搜索
使用声明式DSL(domain-specific language)来编写转换规则,让优化器在计划过程中强制使用
使数据库开发人员只需编写用于优化查询的声明式规则,由优化器充当编译器的角色来自动地确定等价规则,并在优化过程中执行这些规则。
允许数据库的实现人员编写声明式的规则优化查询
分层搜索
分层搜索利用了优化器生成器,在数据库内维护的不再是一个规则列表,而是一个规则引擎。在优化时,规则引擎以最初的逻辑计划为输入,会自动生成出需要使用的规则
Starburst优化器(使用声明式规则):
- 查询重写:计算一个SQL块级的的查询关系演算表示
- 物理优化:执行与R系统类似的动态规划
优点:实现简单,实践中验证了其高效性
缺点:难以确定转换规则执行顺序,由于在转换时完全不考虑代价的估计,一些转换的好坏在选择前难以进行评估,维护转换规则比较困难。
统一搜索
Cascades采用的优化方法,仍在MSSQL和Greenplum数据库中被使用。
在统一搜索策略下,逻辑到逻辑的转换与逻辑到物理的转换都被统一成同一阶段进行的转换
- 整个查询计划的确定都在同一个阶段利用搜索完成。
- 产生了许多转换,因此会大量使用了记忆化,以减少重复的计算(自顶向下)
优点:使用声明式规则生成等价转换,利于添加新规则,规则扩展性好, 利用记忆化减少冗余的计算,可以提前剪枝,提升表数较多时的计划生成速度。
缺点:所有的等价转换都会被使用,生成出所有可能的逻辑计划,逻辑规则较多时,优化代价高
Cascades优化器(统一搜索)
自顶向下迭代使用规则进行优化,整个搜索空间会形成一个Operator Tree的森林。
将一组逻辑上等价的逻辑表达式以及它们对应的所有物理表达式定义为一个组
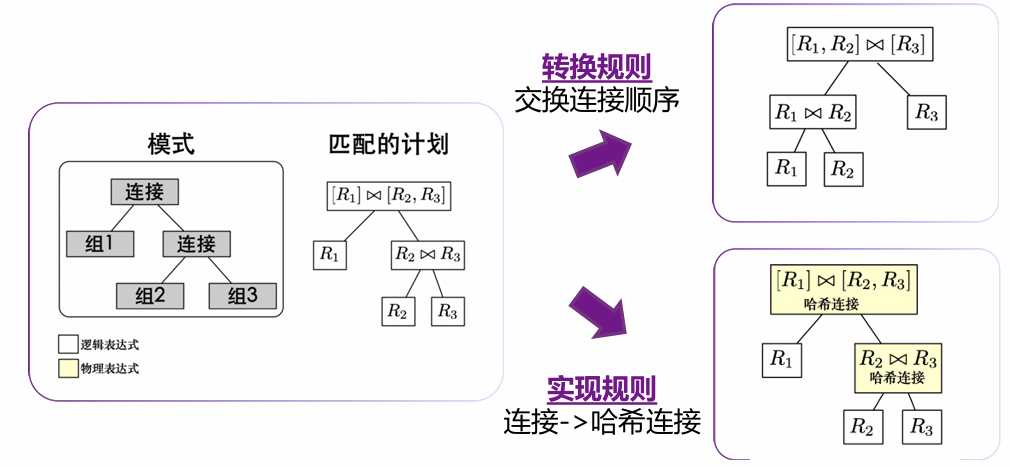
逻辑1逻辑Implementation:逻辑算子可以转换成物理算子;例如Join转换成NestLoop或者HashJoin等
逻辑2物理Transformation:逻辑算子可以做等价变换;例如交换Inner Join的两个子节点,即可枚举Join顺序
探索更多的表达式,按优先级对转换规则进行排序,并在搜索过程中,动态地调整排序
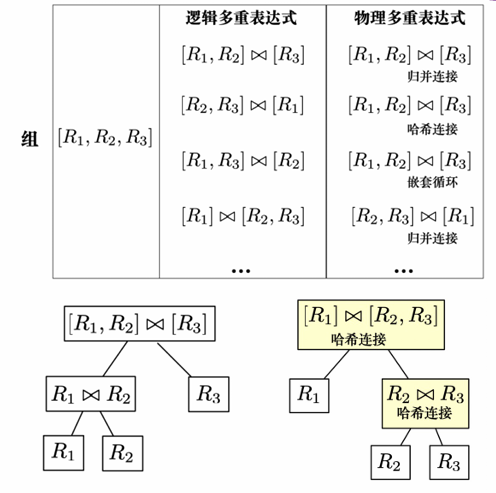
概念解释:
- 逻辑表达式:例如 (R1⋈ R2) ⋈ R3
- 物理表达式:例如 (R1⋈归并连接 R2) ⋈嵌套循环 R3
- 组:一组逻辑上等价的逻辑表达式以及它们对应的所有物理表达式

- 多重表达式:优化器不将一个组中所有可能的表达式实例化,而是隐式地将一个组中重复的表达式表示为一个多重表达式,减少了变换个数,从而节省了空间开销,避免了重复的代价估计。
- 规则:规则是将一个表达式转换为逻辑等价的表达式。每个规则都可以表示为一对属性
- 模式Pattern:定义可以应用规则的逻辑表达式的结构
- 替换Substitute:定义应用规则产生的结果结构
物化与流水线
使用流水线执行能够减少磁盘的I/O,因而在内存足够的情况下流水线方法一般总是更好的选择。
- 物化:将每个运算的结果存储为磁盘上的临时关系,会带来大量磁盘读写的开销
- 流水线:得到一个操作的部分结果时就会将数据传递到下一个操作中,避免了临时文件的读写
能够流水线执行的运算需要像选择、投影运算一样,在收到部分输入元组后就可以开始输出运算产生的结果元组。
存在阻塞的算子不能流水线执行。
例子:
- 哈希连接需要先对内外关系建立哈希表,在没有收到完整的输入元组前无法完成,因此无法流水线执行
- 而如果要进行连接的两个关系都是有序的,归并连接就是可以流水线执行的
物化视图
- 视图:一个经过命名存储在数据库中的查询,又被称为“虚关系”
- 物化视图:将定义视图的结果存储到磁盘上,减少重复查询,空间换时间
例如:有SQL是个频繁执行的查询,则可以将该查询按如下SQL语句声明为一个物化视图存储在磁盘上
物化视图的维护方式
当定义物化视图的基表数据发生改变时,如何保证物化视图的数据能够高效地被更新
当基本关系发生变化时,需要对物化视图进行更新,从而使物化视图与其派生自的基本关系保持一致
按照何时更新可分为:立即视图维护和延迟视图维护
视图维护方式可分为:重新建立视图和增量视图维护
总结