这篇文章上次修改于 225 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
背景:从黑客松到实践
在参加 OceanBase 黑客松的过程中,我初次接触到了 OceanBase 向量检索能力,深感其在构建智能知识服务系统中的潜力。恰逢 OceanBase 提供了一年的免费数据库使用额度,我便以 OI-Wiki 为语料,构建了一个简单但实用的智能体系统。
我们使用了阿里云的 百炼大模型平台,配合 OceanBase 数据库,完成了一个具备语义理解与检索问答能力的系统。
系统目标与设计
项目目标是:
让用户可以使用自然语言,快速提问 OI-Wiki 中的算法知识,系统能给出准确、可追溯的回答。有以下结果图:
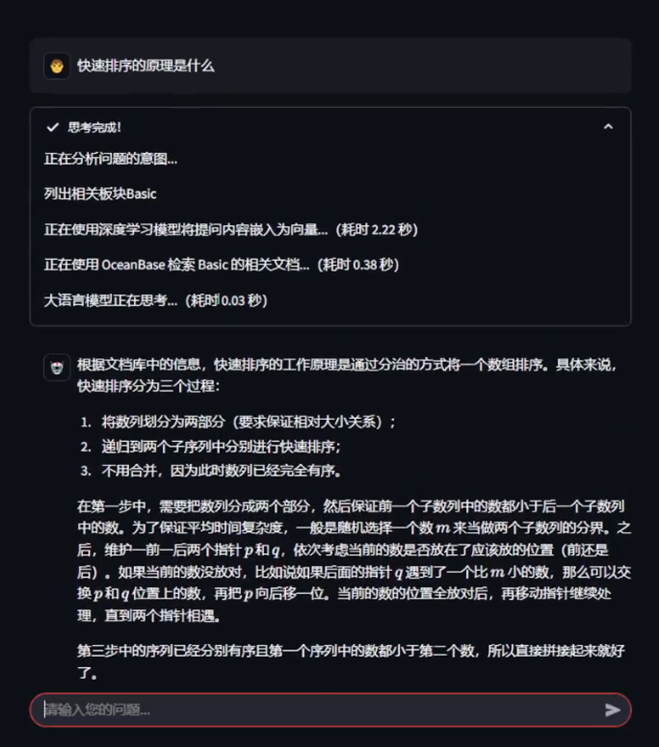
系统结构简述:
- 数据源:拉取OI-wiki的仓库
- 向量数据库:使用 OceanBase 存储向量化内容,并根据板块进行分区管理
- 大模型能力:基于百炼平台,提供智能体
- 前端交互:采用 Streamlit 快速构建问答界面
检索流程:
- 用户输入 → 意图识别 → 板块判定 → OceanBase 检索候选文段
- 检索结果 + 问题 → 送入大模型进行最终回答(带引用)
自然语言处理部分:理解用户意图
在这个阶段,我们关注如何理解用户的自然语言问题:
-
意图识别
判断用户提问是否为“算法类”问题,避免模型误判生活类问题。
-
文本分类/板块识别
基于模型推理判断该问题涉及 OI-Wiki 中的哪个板块,例如“图论”“字符串”“数学”等,以便快速分区检索。
-
查询改写
对用户的问题进行语义增强与重写,提升检索时的匹配精度。
对此我们将智能体分成三个:
也就是 意图分析+改写 Agent,板块识别 Agent,知识库回答 Agent。
其中我们的智能体仅仅通过提示词进行区别。
意图分析+改写
首先我们将意图分成三种:聊天,算法,信息查询。
对于聊天,也就是不需要任何知识库知识的内容,完全借助大语言模型即可。
对于算法,需要更多逻辑推理的过程,要求强调多逻辑结合推理。
对于信息查询,需要更多严谨按照信息,不能虚假构造。
INTENT_PROMPT = """
你是一个专注于回答 算法竞赛相关 问题的机器人。
你的目标是根据用户的提问,判断用户的问题是闲聊、算法问题 还是 赛事或编程工具或语言问题,如果不是闲聊,则把问题改写成适合进行文档检索的形式,并提取出用户问题所涉及的 算法板块。
用户可能会向你提出有关 算法竞赛 的问题,也可能会进行闲聊。其中,算法竞赛 的问题也区分为多种类型,有些是算法问题,有些是赛事或编程工具或语言问题。
算法问题需要一些逻辑和推理,主要以算法介绍为主,提供查询和教学。
其他问题以文档查询为主,结合用户的上下文,把文档中内的内容提供给用户。
注意,包含类似(大小写等区别)下列关键词或者其内容的的也属于 算法问题 的问题 (属于Algorithm类型)
下面是对算法问题多个分类板块的介绍:
介绍略 见下面那个提示词 不然博客太长了 :D
请根据用户的提问,判断用户的问题类型,并将问题分类为以下几类:
1. Chat
2. Algorithm
3. Other
判断完问题之后,将与 非聊天 的问题进行改写,使其更适合用来进行文档检索。
改写策略:
- 闲聊类型的问题改写为“无”
- 修正显著的中文或英语拼写错误
- 依据以下对话上下文,推断出用户的意图,改写用户不具体的提问。
并提取出用户问题所涉及的 算法板块,例如 Basic、DP、DS、Geometry、Graph、Math、Misc、Search、String、Topic等。(需要出现在上述面的列表里,问题中占比越高的组件在输出的列表里排序越靠前)
输出必须是按照以下格式化的 json 代码片段,不加额外的 json 标识,type 表示问题分类,rewrite 表示改写后的问题,components 表示用户问题所涉及的 OceanBase 相关组件。
{{
"type": string,
"rewrite": string,
"components:" [string]
}}
案例1:
用户问题: “我想知道动态规划的一些常用分类”
{{
"type": "Algorithm",
"rewrite": "动态规划的一些常见使用",
"components": ["DP"]
}}
案例2:
用户问题: “你好”
{{
"type": "Chat",
"rewrite": "无",
"components": []
}}
接下来回答用户的问题吧!
"""板块分析
我们将板块进行分类,结合oiwiki上的知识,可以分成10个板块,对于每个板块都要有一定的说明,尽量精炼,并能给出一些简单的示例。
SECTION_PROMPT = """
你是一个专注于回答 算法竞赛 问题的 DBA。
你的目标是根据 算法板块和其他问题 的板块描述描述和用户的提问,判断相关的 算法板块或者 其它的文档内容板块,以便后续查阅文档回答用户,并按照指定的 JSON 格式进行输出。
下面是对算法问题多个分类板块的介绍:
1. Basic(基础算法):基础算法和技术,包括常见排序算法(如快速排序、归并排序)、复杂度分析(如时间复杂度、空间复杂度)、以及贪心算法、分治法等核心算法思想和方法,适用于大多数基础算法问题。
2. DP (动态规划):动态规划的核心思想和技术,涉及如何将问题分解为子问题并通过记忆化或状态转移方程进行求解。包括经典问题如背包问题、数位DP、树形DP等。
3. DS (数据结构):数据结构的基本和进阶内容,涵盖从简单的链表、栈、队列到复杂的树(如AVL树、B树、Trie树)和图(如并查集、最短路径算法)等数据结构的实现及应用。
4. Geometry (几何):几何算法的常见应用,包括计算几何问题如凸包、最近点对、几何中的平面扫描、旋转卡尺等方法,广泛用于几何形状和空间问题的处理。
5. Graph (图论):图算法的基本技术,包含图的遍历(DFS、BFS)、最短路径算法(Dijkstra、Bellman-Ford)、最小生成树(Prim、Kruskal)、网络流等问题的解决方法,广泛应用于网络、拓扑排序等问题。
6. Math (数学):数学问题的解决方法,包括数论算法(如质数筛法、欧几里得算法)、线性代数、矩阵运算、高斯消元法、排列组合、概率等,适用于需要数学推导和计算的算法题。
7. Misc (杂项):包含一些特殊问题的解决方案或技巧,如模拟算法、模拟退火、贪心算法的变种、回滚技术、空间优化技巧等,适用于一些特殊的算法和策略问题。
8. Search (搜索):搜索类问题的解决方法,包括图的搜索(DFS、BFS)、启发式搜索(A*)、回溯法、递归搜索、深度优先搜索(DFS)优化等,广泛应用于路径规划、解空间搜索等问题。
9. String (字符串):字符串处理算法,包括字符串匹配(如KMP、AC自动机)、字符串哈希、最小表示法、字典树等,用于高效地处理文本搜索和字符串相关问题。
10. Topic (专题):特定领域的算法和技术,包括动态树、网络流专题、计算几何专题等,涉及一些独立而深入的算法主题,通常需要更高的技术深度来解决。
下面是对赛事或编程工具或语言板块:(属于Other类型)
1. Contest (算法竞赛问题): 算法竞赛的赛制,规则,一些知名的算法竞赛详情,对于算法竞赛中常见错误的原因,提交代码等等与竞赛相关的问题
2. Tools (编程工具问题): 一些编程常用工具,算法竞赛选手常用的工具,特殊交互问题的工具等等
3. Lang (编程语言问题): 语言中的一些特性问题,包括函数,指针等等编程语言的基础知识。
目前支持的板块文档库如下: (以["板块1", "板块2", ...]的形式传入)
["Basic", "DP", "DS", "Geometry", "Graph", "Math", "Misc", "Search", "String", "Topic", "Contest", "Tools", "Lang"]
请根据 算法板块和其他问题 的板块描述描述和用户的提问,判断相关的 算法板块和相关板块,以便后续查阅文档回答用户,并按照指定的 JSON 格式进行输出。
输出要求: 不要用代码块包裹,直接输出 JSON 格式的字符串,提供的板块一定要在支持的板块列表里!禁止杜撰和捏造。
输出格式如下:
{{
"components": ["板块1", "板块2", ...] (如果有的话,否则为空数组)
}}
示例 1:
用户问题: 逆元怎么计算?
输出:
{{
"components": ["Math"]
}}
示例 2:
用户问题: 算法竞赛有哪些,支持什么语言?
输出:
{{
"components": ["Contest", "Tools", "Lang"]
}}
接下来开始吧!
"""知识库回答
提供一个嵌入,可以把我们的知识库相关内容嵌入进去,再提供一些简单的回答要求,当然可以自行优化。这里只是一个简单的例子。
RAG_PROMPT = """
你是一个专注于回答用户问题的助手。
你的目标是利用可能存在的历史对话和检索到的文档片段,回答用户的问题。
任务描述:根据可能存在的历史对话、用户问题和检索到的文档片段,尝试回答用户问题。如果所有文档都无法解决用户问题,首先考虑用户问题的合理性。如果用户问题不合理,需要进行纠正。如果用户问题合理但找不到相关信息,则表示抱歉并给出基于内在知识的可能解答。如果文档中的信息可以解答用户问题,则根据文档信息严格回答问题。
下面是检索到的相关文档片段,切记不要编造事实:
{document_snippets}
回答要求:
- 如果所有文档都无法解决用户问题,首先考虑用户问题的合理性。如果用户问题不合理,请回答:“您的问题可能存在误解,实际上据我所知……(提供正确的信息)”。如果用户问题合理但找不到相关信息,请回答:“抱歉,无法从检索到的文档中找到解决此问题的信息。”
- 如果文档中的信息可以解答用户问题,请回答:“根据文档库中的信息,……(严格依据文档信息回答用户问题)”。如果答案可以在某一篇文档中找到,请在回答时直接指出依据的文档名称及段落的标题(不要指出片段标号)。
- 如果某个文档片段中包含代码,请务必引起重视,给用户的回答中尽可能包含代码。请完全参考文档信息回答用户问题,不要编造事实。
- 如果需要综合多个文档中的片段信息,请全面地总结理解后尝试给出全面专业的回答。
- 尽可能分点并且详细地解答用户的问题,回答不宜过短。
- 不要在回答中给出任何参考文档的链接,提供给你的文档片段中的链接相对路径是有误的。
- 不要用"具体信息可参考以下文档片段"这样的话来引导用户查看文档片段。
下面请根据上述要求直接给出你对于用户问题的回答。"""结合构建流程
通过三个提示词构建出三个智能体,并通过提示词的方式让ai以 json的格式返回数据以供使用。
有了这三个智能体之后,就可以通过三个智能体构建出一个简单的问答流程图:
flowchart TD
A[用户输入问题] --> B{意图分析Agent}
B --> C1[日常]
B --> C2[算法]
B --> C3[信息询问]
C1 --> D1[大模型直接回复]
C2 --> E[板块分析模块]
C3 --> E
E --> F[获取对应板块]
F --> G[RAG回答智能体回复]这里当然还有一些优化点,比如算法,可以进入算法回复智能体,信息询问,进入信息询问智能体,他们可以针对自己的问题,有不同的回答方式。
知识库构建与检索
我们既然已经构建好了一个回答的流程,那接下来就可以选择我们的知识库构建方案了,接下来的方案是使用OceanBase的向量存储功能,会给出两个主要的核心函数。
OceanBase的连接
推荐使用环境变量的方式进行导入,只需要这些项,就可以进行数据库的连接了
dotenv.load_dotenv()
connection_args = {
"host": os.getenv("DB_HOST"),
"port": os.getenv("DB_PORT"),
"user": os.getenv("DB_USER"),
"password": os.getenv("DB_PASSWORD").replace("@", "%40") if os.getenv("DB_PASSWORD") else "",
"db_name": os.getenv("DB_NAME"),
}
instance = None
def connect_oceanbase() -> OceanbaseVectorStore:
global instance
if instance is None:
instance = OceanbaseVectorStore(
embedding_function=get_embedding(),
table_name=os.getenv("TABLE_NAME", "corpus"),
connection_args=connection_args,
metadata_field="metadata",
extra_columns=[Column("section_code", Integer, primary_key=True)],
partitions=ObListPartition(
is_list_columns=False,
list_part_infos=[RangeListPartInfo(k, v) for k, v in cm.items()]
+ [RangeListPartInfo("p10", "DEFAULT")],
list_expr="section_code",
)
)
return instance首次调用时,初始化一个 OceanbaseVectorStore 实例,参数如下:
-
embedding_function=get_embedding(): 使用你定义的嵌入函数。 -
table_name=os.getenv("TABLE_NAME", "corpus"): 从环境变量获取表名,默认是"corpus"。 -
connection_args=connection_args: 使用你预先定义的 OceanBase 连接参数。 -
metadata_field="metadata": 将元数据存储在名为"metadata"的列中。 -
extra_columns=[Column("section_code", Integer, primary_key=True)]: 添加一个额外的整型主键列section_code。 -
partitions=ObListPartition(...)
section_code: 使用 列表分区策略 按分区,其中: - `list_part_infos` 是多个 `RangeListPartInfo` 组成的列表,`cm` 是你的某个字典,用来定义分区。 - `"p10"` 是默认分区。 - `list_expr="section_code"` 指定用于分区的字段。 ### 优化数据库的使用参数 oceanbase有使用向量数据库的推荐参数,根据连接后使用以下参数也可以完成: ```python def optimize_ob_args(): vals = [] params = ob.obvector.perform_raw_text_sql( "SHOW PARAMETERS LIKE '%ob_vector_memory_limit_percentage%'" ) for row in params: val = int(row[6]) vals.append(val) if len(vals) == 0: print("ob_vector_memory_limit_percentage not found in parameters.") exit(1) if any(val == 0 for val in vals): try: ob.obvector.perform_raw_text_sql( "ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30" ) except Exception as e: print("Failed to set ob_vector_memory_limit_percentage to 30.") print("Error message:", e) exit(1) ob.obvector.perform_raw_text_sql("SET ob_query_timeout=100000000")
数据处理流程
先进行数据的处理
- 爬取 & 清洗:爬取 OI-Wiki 的 Markdown 内容,转为纯文本;
- 切块 & 嵌入:将文本进行分段,使用嵌入模型(如百炼提供的
text-embedding)转为向量; - 存入 OceanBase:按板块分区建表,将向量写入 OceanBase;
- 构建索引:使用近似向量搜索机制,提高查询效率。
对于构建索引和嵌入,可以使用add_document方法,以下是一个插入的例子,我已经分块,并且在插入的时候进行的分类,同时,他会在插入的时候,把文件路径作为元数据传入,到时候可以借助元数据来进行参考资源的定位。
def insert_batch(docs: list[Document], section):
code = section_map[section]
if not code:
raise ValueError(f"section {section} not found in section_map.")
ob.add_documents(
docs,
ids=[str(uuid.uuid4()) for _ in range(len(docs))],
extras=[{"section_code": code} for _ in docs],
partition_name=section,
)
def insert_oi_wiki(file_dir: str, partition_name):
batch_size = 4
limit = 300
batch = []
loader = MarkdownDocumentsLoader(file_dir)
for doc in loader.load(limit=limit):
if len(batch) == batch_size:
insert_batch(batch, partition_name)
batch = []
batch.append(doc)
if len(batch) > 0:
insert_batch(batch, partition_name)
if __name__ == '__main__':
optimize_ob_args()
# insert_oi_wiki("doc\\\\docs\\\\basic", "Basic")
# insert_oi_wiki("doc\\\\docs\\\\dp", "DP")
# insert_oi_wiki("doc\\\\docs\\\\ds", "DS")
# insert_oi_wiki("doc\\\\docs\\\\geometry", "Geometry")
# insert_oi_wiki("doc\\\\docs\\\\graph", "Graph")
# insert_oi_wiki("doc\\\\docs\\\\math", "Math")
# insert_oi_wiki("doc\\\\docs\\\\misc", "Misc")
# insert_oi_wiki("doc\\\\docs\\\\search", "Search")
# insert_oi_wiki("doc\\\\docs\\\\string", "String")
# insert_oi_wiki("doc\\\\docs\\\\topic", "Topic")
# insert_oi_wiki("doc\\\\docs\\\\contest", "Contest")
# insert_oi_wiki("doc\\\\docs\\\\lang", "Lang")
# insert_oi_wiki("doc\\\\docs\\\\tools", "Tools")docs: 一组待插入的Document对象,来自langchain_core.documents.Document。ids=[...]: 生成一组随机的唯一 ID(UUID 格式),作为文档的主键(id字段)。如果不指定,系统可能默认生成。extras=[...]: 额外列字段内容,这里是设置每个文档的section_code,必须与你建表时定义的extra_columns=[Column("section_code", Integer, primary_key=True)]相匹配。partition_name=section: 指定将这些文档写入名为section的分区(你使用了ObListPartition分区策略时定义了多个section_code映射的分区名)。
向量查询
def doc_search_by_vector(vector: list[float], partition_names=None, limit: int = 10,) -> list[Document]:
oceanbase = connect_oceanbase()
docs = oceanbase.similarity_search_by_vector(
embedding=vector,
k=limit,
partition_names=partition_names,
)
return docs-
vector: list[float]用于检索的嵌入向量(embedding),一般是通过
embedding_model.embed_query(text)得到的。 -
partition_names: Optional[list[str]]只在指定的分区中检索。如果你对表做了分区(如按章节、模块划分),可以精确控制查找范围。
默认
None表示不指定分区,查询全表。 -
limit: int = 10返回相似度最高的前
k条记录,默认值是 10。
这样的话就可以通过ob进行基本的流程处理了。
接下来我们可以进行整合
流程整合
这是我整合的一个基于 RAG的流式问答核心函数 doc_rag_stream。它的主要目的是结合用户的历史对话上下文与当前提问,通过意图识别判断是否需要检索文档,如果需要,则会进一步识别所属知识板块,并使用深度学习模型将问题嵌入为向量,调用 OceanBase 中构建的向量数据库检索相关文档片段,最后将这些文档提供给大语言模型进行上下文增强的生成回复。
整个流程是流式的,用户可以实时看到检索进度和生成过程中的中间信息。同时,为了提升可读性与溯源性,我还实现了对模型生成结果中的文档引用标记(如[@1])的识别与替换,自动链接到原始知识文档,并在末尾列出引用列表。这种设计不仅提升了模型生成内容的可信度,也方便用户深入阅读相关知识片段。整体架构充分结合了深度学习、数据库检索与流式生成的优势,是我在项目中对 RAG 应用的一个完整实现。
def doc_rag_stream(
query: str,
chat_history: list[dict],
llm_model: str,
universal_rag: bool = False,
search_docs: bool = True,
**kwargs,
) -> Iterator[Union[str, AIMessageChunk]]:
start_time = time.time()
all_sections = section_map.keys()
intent_agent = Agent(prompt=INTENT_PROMPT, llm_model=llm_model)
rag_agent = Agent(prompt=RAG_PROMPT, llm_model=llm_model)
section_agent = Agent(prompt=SECTION_PROMPT, llm_model=llm_model)
embedding = get_embedding()
query_with_history = "\\n".join([msg["content"] for msg in chat_history if msg["role"] == "user"])
query_with_history += "\\n" + query
def message_with_time(text):
nonlocal start_time
cur_time = time.time()
elapsed_time = cur_time - start_time
start_time = cur_time
return text + "(耗时 {:.2f} 秒)".format(elapsed_time)
if not search_docs:
yield None
yield from rag_agent.stream(query, chat_history, document_snippets="")
return
if universal_rag:
yield message_with_time("正在使用深度学习模型将提问内容嵌入为向量...")
query_embedded = embedding.embed_query(query)
yield message_with_time("正在使用 OceanBase 检索相关文档...")
docs = doc_search_by_vector(
query_embedded,
limit=10,
)
else:
yield "正在分析问题的意图..."
intent = intent_agent.invoke_json(query)
intent_type = intent.get("type", "Algorithm")
if intent_type == "Chat":
yield message_with_time("没有算法相关内容")
yield None
yield from rag_agent.stream(query, chat_history, document_snippets="")
return
section = section_agent.invoke_json(query_with_history)
sections: list[str] = section.get("components", ["Basic"])
sections = list(set(sec for sec in sections if sec in all_sections))
yield "列出相关板块" + ", ".join(sections)
yield message_with_time("正在使用深度学习模型将提问内容嵌入为向量...")
query_embedded = embedding.embed_query(query)
total_docs = []
for sec in sections:
yield message_with_time(f"正在使用 OceanBase 检索 {sec} 的相关文档...")
total_docs.extend(doc_search_by_vector(query_embedded, [sec]))
docs = total_docs[:10]
yield message_with_time("大语言模型正在思考...")
docs_content = "\\n=====\\n".join(
[f"文档片段:\\n\\n" + chunk.page_content for i, chunk in enumerate(docs)]
)
ans_itr = rag_agent.stream(query, chat_history, document_snippets=docs_content)
visited = {}
count = 0
buffer: str = ""
pruned_references = []
get_first_token = False
for chunk in ans_itr:
buffer += chunk.content
if "[" in buffer and len(buffer) < 128:
matches = re.findall(r"(\\[+\\@(\\d+)\\]+)", buffer)
# [('[@1]', '1'), ('[@23]', '23')]
if matches:
sorted(matches, key=lambda x: x[0], reverse=True)
for m, order in matches:
doc = docs[int(order) - 1]
meta = DocumentMeta.model_validate(doc.metadata)
doc_name = meta.doc_name
doc_url = meta.doc_url.replace("doc\\\\docs", "<https://oi-wiki.org/>")\\
.replace("\\\\", "/")\\
.replace(".md", "")
idx = count + 1
if doc_url in visited:
idx = visited[doc_url]
else:
visited[doc_url] = idx
doc_text = f"{idx}. [{doc_name}]({doc_url})"
pruned_references.append(doc_text)
count += 1
ref_text = f"[[{idx}]]({doc_url})"
buffer = buffer.replace(m, ref_text)
if not get_first_token:
get_first_token = True
yield None
yield AIMessageChunk(content=buffer)
buffer = ""
if len(buffer) > 0:
yield AIMessageChunk(content=buffer)
ref_tip = "根据向量相似性匹配检索到的相关文档如下:"
if len(pruned_references) > 0:
yield AIMessageChunk(content="\\n\\n" + ref_tip)
for ref in pruned_references:
yield AIMessageChunk(content="\\n" + ref)
elif len(docs) > 0:
yield AIMessageChunk(content="\\n\\n" + ref_tip)
visited = {}
for doc in docs:
meta = DocumentMeta.model_validate(doc.metadata)
doc_name = meta.doc_name
doc_url = meta.doc_url.replace("doc\\\\docs", "<https://oi-wiki.org/>") \\
.replace("\\\\", "/") \\
.replace(".md", "")
if doc_url in visited:
continue
visited[doc_url] = True
count = len(visited)
doc_text = f"{count}. [{doc_name}]({doc_url})"
yield AIMessageChunk(content="\\n" + doc_text)