这篇文章上次修改于 586 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
ARISE 优化策略
基于undo/redo日志
回顾undo/redo日志的恢复算法缺陷:
- 部分redo日志无需重做:已经刷脏的日志不需要redo
- undo操作无需扫描全部日志
- undo日志恢复期间故障恢复问题:undo的redo
- 故障恢复执行时间过长:模糊检查点和增量检查点
ARISE优化策略就针对以上缺陷作为优化点,进行优化:
部分redo无需重做
回顾何时redo:
系统从日志起始位置开始扫描整个日志,找出需要重做的事务,再对所有对应标记的事务进行重做。
问题提出
为什么要重做:因为重做中,很多修改都存于脏页之中,脏页处于非持久储存的缓存,但事实上,有些存于脏页可能因为淘汰或者其他机制被刷脏到持久存储中,那么这些重做就没有必要了。
数据库无法得知redo日志对应页面最后一次写入磁盘的时刻,无法判断脏页是否被刷盘。
解决方法
如果知道每一个脏页刷盘时间,就可以避免不必要的重做。
引入脏页表,记录哪些页面更新了没刷盘
引入检查点,检查点之前的已经刷盘无需重做
因此,事件发生的先后关系是我们需要知道的:可以采用LSN来作为逻辑时间成为判断标准。
LSN和PageLSN
LSN全称:Log Sequence Number代表日志的序列号,表示了出现的顺序。
关于日志记录的格式,实际如下:
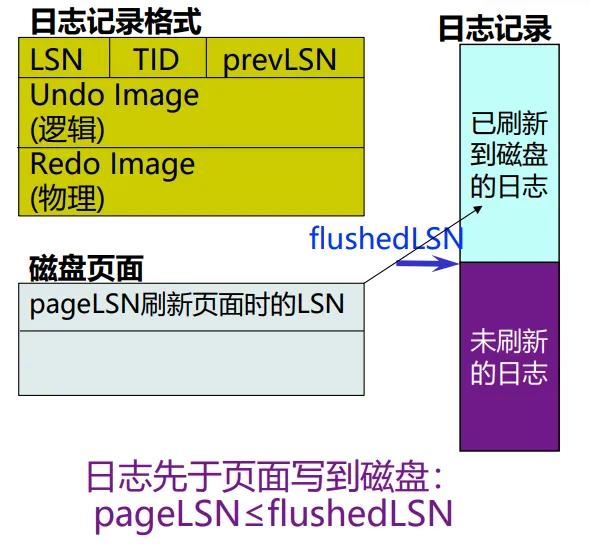
prevLSN指的是事务的前一项LSN。PageLSN代表数据页面最近更新的时刻。
异步刷新日志记录flushedLSN,刷新到磁盘的最大日志LSN。
如果有一个事务,它的最后一条commit记录的LSN小于flushedLSN,说明它的所有日志都被刷下去了。
脏页表
脏页表是一个二维表,里面有两个字段:
- PageID:页面的标识符
- RecLSN:数据页面最早在缓冲区被修改的LSN时刻
更新时机:
- 页面第一次被事务修改:添加到脏页表
- 页面非第一次被修改:无需处理
- 页面被写回磁盘:从脏页表中删除
使用方法:
判断日志记录是否要被重做,从哪里开始重做。
- 若日志记录的PageID不在脏页表,则不需要重做
- 如果日志记录LSN ≤ RecLSN 说明数据修改已经在磁盘中生效,不需要重做。
然而脏页表也和数据一样,如果数据因为崩溃没有写入成功,那么脏页表也有可能因为崩溃导致没有写入成功。
解决方式就是使用checkpoint位置的脏页表进行重现。
Undo操作无需扫描全部日志
例子:
对于三个事务的undo来说,如果两个事务已经commit,一个事务需要被回滚,那么实际上,undo操作只要扫描这一个事务的日志即可,无需遍历所有日志。
活跃事务表(未结束的事务表)
追踪数据库中所有未结束的事务
是一个二维表,有两个字段:
- TID:事务id
- LastLSN:与对应事务相关的最后一个日志记录LSN
PrevLSN
我们可以通过活跃事务表找到最后一个日志记录LSN,也就可以通过最后一个事务的PrevLSN像链表一样从后往前只遍历这一个事务的日志。
Undo日志恢复期间故障恢复
回顾undo日志,假设我们现在正处于undo的操作中,回滚到了一半,崩溃了,也就是恢复期间故障。
我们要知道哪些undo日志已完成了哪些,哪些还未完成。然后进行redo。
进行redo很好理解,那就是创建一个undo日志的redo日志(补偿日志)
如果崩溃继续redo这个undo即可。
UndoNextLSN
CLR(Compensation Log Record,补偿日志记录)
在数据库事务的恢复过程中,当需要进行回滚操作时,数据库系统会生成CLR来记录回滚操作的补偿信息。CLR确保在回滚期间不会重复执行已经撤销的操作,从而避免系统状态的不一致。
UndoNextLSN位于每条CLR中,代表事务下一条要回滚的日志记录的LSN
ARISE算法的WAL
ARIES算法使用了undo/redo日志,因此也需要满足预写日志的条件。
- ARIES中含有FlushedLSN字段,表示写入磁盘日志最大的LSN
- 脏页写回磁盘时,需满足PageLSN <= FlushedLSN
- 事务提交时需要满足LastLSN <= FlushedLSN
- ARIES中日志记录会批量定时从内存写回磁盘,每次写入完成时会更新FlushedLSN
日志太多导致恢复时间过长
采用了数据库检查点解决此问题。
磁盘中有个Master record字段,表示最新一次检查点的位置。
全量检查点
- 为了减少日志,数据库系统会定时执行检查点操作
- 将所有磁盘上的脏页刷回磁盘
- 全量检查点执行:等待缓冲区刷脏(截断日志 – 已经刷盘,不需要的日志 – 可以回收)
- 全量检查点过程中需要写回全部脏页面,占用大量IO资源
通常在数据库关闭时,恢复后生成一致的基线,手动触发等情况会进行全量检查点记录,需要将所有脏页刷脏。在设置全量检查点的时候需要一定时间,期间无法处理事务。
流程:
- 由写入
开始,由写入 结束 - 中间过程将内存中的脏页表和事务表写入磁盘
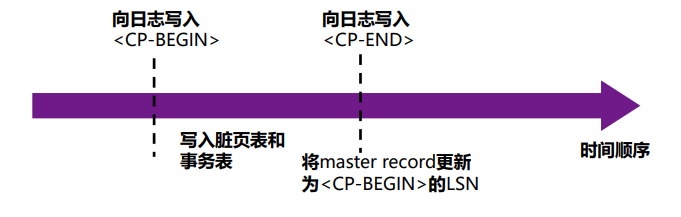
模糊检查点
整个检查点过程分成:
- 开始检查点
- 结束检查点
- 中间过程写入脏页表和事务表
模糊检查点由主动转为被动,跟随事务进行的情况,系统会记录结束检查点,结束检查点会将事务表和脏页表的最终状态记录下来,并标记检查点过程的结束。 一旦记录了结束检查点,下一次的开始检查点通常是从上一次的结束检查点开始。
恢复时通过脏页表和事务表还原数据库状态,脏页表中存储了未被刷盘的脏页,从未结束的开始检查点进行恢复。
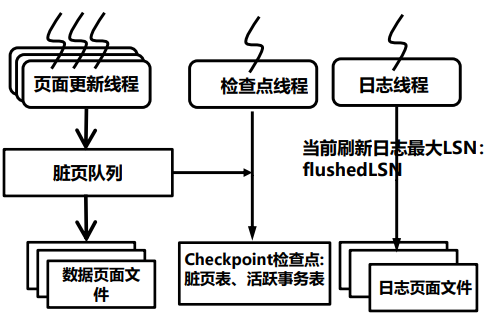
流程:
- 不需要全量脏页刷盘,单独线程刷新,优化检查点执行速度
- 脏页表和活跃事务表服务于模糊检查点机制
- 在checkpoint检查点记录脏页表(DPT)和活跃事务表(ATT)的内容。
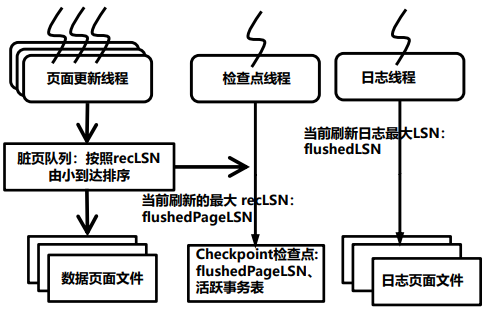
增量检查点
不需全量脏页刷盘,增量刷新脏页,优化检查点执行速度
- 单独线程刷新脏页 按照脏页的RecLSN排序 按照RecLSN由小到大刷新脏页
- 在checkpoint检查点记录 当前刷新脏页的最大LSN为FlushedPageLSN 活跃事务表ATT(事务提交日志)
- 恢复时 从FlushedPageLSN日志开始重建脏页表和活跃事务表
总结:
- 重做阶段不必要的数据页面更新:引入脏页表,更新前通过比较检查,优化更新效率
- 撤销阶段不必要的日志扫描:引入活跃事务表和prevLSN,跳过不相关的日志记录
- 撤销阶段的故障恢复:引入补偿日志和undoNextLSN字段,确保 撤销只执行一次
- 日志太多导致恢复时间过长:引入模糊检查点和增量检查点,优化了恢复速度
ARISE架构

ARISE流程
- SQL语句经过一系列变换转化成物理执行计划
- 在缓冲区上读写数据页面
- 日志记录写入缓存
- 更新事务表和脏页表
- 事务LSN刷新到磁盘 lastLSN≤flushedLSN (异步)
- 刷脏线程定时写回脏页
- 刷脏时更新脏页表
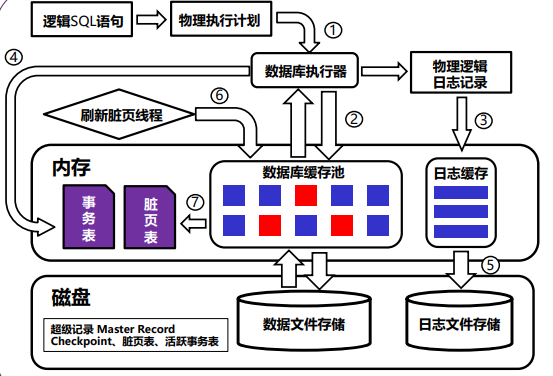
ARISE工作步骤
记录
实时记录日志
实时更新活跃事务表和脏页表
活跃事务表:事务开始时加入,结束时删除。根据LSN更新LastLSN
脏页表:Page第一次修改的时候加入,并记录recLSN。Page刷盘时删除(内存、磁盘一致时删除)。
异步刷新页面并更新FlushedLSN,并记录pageLSN
异步增量检查点checkpoint。
Checkpoint记录当前脏页表和活跃事务表信息。
恢复
构造模拟脏页表和活跃事务表
从checkpoint开始扫描日志 (LSN, TID, PageID, Op)
① 更新活跃事务列表
- 如果TID 在活跃事务列表 如果OP是Commit,把TID从活跃事务表删除 否则更新活跃事务列表(TID, LastLSN) = (TID, LastLSN = LSN);
- 如果TID不在活跃事务列表 将该事务加入活跃事务列表(TID, LastLSN = LSN)
② 更新脏页表
- 如果PageID不在脏页表将(Page, recLSN=LSN)加入脏页表
- 如果PageID在脏页表,跳过不处理 PageID刷盘时,从脏页表将PageID删除
重做(利用脏页表)
准备阶段:
选择脏页表中最小的RecLSN作为重做阶段开始位置
如果脏页表为空,重做阶段开始位置为开始检查点记录的位置
流程:
自脏页表中min(RecLSN)开始从前向后扫描,判断是否需要重做:
- 如果日志记录的pageID不在脏页表中,不需要重做
- 如果日志记录LSN < RecLSN,数据修改已在磁盘中生效,不需要重做
- 如果日志记录LSN >= RecLSN,从磁盘读到缓冲区,如果LSN <= PageLSN,不需要重做
- 以上条件均不满足,重做日志记录
根据日志更新记录修改缓冲区数据项,更新脏页表和活跃事务表。
撤销(利用活跃事务)
准备阶段:(构建事务表)
对于每一条日志记录,读取事务ID,插入/更新事务表
检查点结束日志记录:读取检查点中事务表,更新缓冲区中事务表
事务结束记录:将事务表从数据项中删除
流程:
- 借助LastLSN、PrevLSN以及UndoNxtLSN从后向前跳跃扫描
- 从活跃事务表根据事务ID找到LastLSN,根据LastLSN找到对应日志记录
- 对日志记录执行撤销操作,依次使用PrevLSN找到下一条要处理的日志
- 一旦PrevLSN = 0,代表到达事务的开始,回滚完成
- 写入该事务中止的日志记录
撤销单条日志记录详细流程:
- 根据日志记录内容修改数据项:通过记录中Undo内容修改,由于是逻辑日志,具体操作由数据库完成
- 更新脏页表:修改数据项后,将对应页面插入脏页表
- 写入补偿日志记录
- 撤销过程中,事务表每一个数据项含有一个新字段UndoNxtLSN,表示事务下一条需要撤销的日志
- 事务每撤销一条日志记录,事务表中的UndoNxtLSN更新为该条日志记录的PrevLSN
日志截断(truncated)
撤销点以前的日志可以删除。判断标准是是否小于min( minLSN(脏页表) , minLSN(活跃事务))
数据库备份技术
ARIES只能处理内存数据丢失一类的故障,无法处理磁盘数据丢失。
可以使用:RAID技术、Paxos技术
常用备份技术:
- 冷备份:备份前需要结束所有数据库中的事务,限制较多,影响在线业务
- 热备份:备份过程中事务,在备份数据的同时也备份数据库重做日志
- 全量备份:备份过程中备份所有数据
- 增量备份:在之前备份的基础上备份增量数据
- 差异备份:在全量备份的基础上备份差异的数据
备份恢复:
- 找到最近的数据库全量备份, 并根据它来恢复数据库(即将备份拷贝到数据库)。
- 如果有后续的增量备份, 按照从前往后做的顺序, 根据各个增量备份修改数据库。
基于时间点的恢复
一种灵活的恢复技术,支持将数据库回推到任意时刻
使用数据备份(全量和增量)和带时间戳的重做日志
- 通过数据备份到恢复某一天
- 通过日志恢复到某一个时刻
数据库闪回
轻量级的数据库回滚技术,借助undo回滚日志、回收站来实现不同粒度的闪回
- 闪回查询:查询过去某个时刻的数据。
- 闪回数据归档:对于undo回滚数据进行归档,使闪回功能支持的时间延长。
- 闪回事务查询:查询过去执行过的某一事务相关的数据。
- 闪回版本查询:查询某个版本范围内的数据。
- 闪回表:将一张数据表的内容回退到一个指定时刻的状态。
- 闪回删除:恢复一张已经被删除的表。
- 闪回数据库:将数据库的所有内容回退到一个指定的时刻。
数据库多机恢复概述
主备模式架构
主站点(primary site)用来处理用户发出的请求 备份站点(backup site)用来做主站点数据的备份,包含了和主站点完全相同的数据。 所有主站点发生的更新会以日志的形式经由网络发送到备份站点上。
两地三中心
在同城、异地建立双数据备份中心,比主备模式更高的安全性
更大的执行代价,需要维护三台以上主机的数据
同城数据传输和异地数据传输代价:
- 同城之间采用同步传输,所有数据不会丢失
- 异地之间采用异步传输,少量数据可能会丢失
