这篇文章上次修改于 589 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
保证事务的原子性和持久性需求:
原子性:
- 事务运行期间不刷盘,系统故障重启后保证原子性。
- 事务运行期间刷盘,系统故障重启后需回滚该事务。
持久性:
- 事务完成时刷盘,故障系统重启后自动保证持久性。
- 事务完成时不刷盘,故障系统重启后需要重做该事务。
数据库故障类别
事务故障:资源冲突和死锁等导致执行失败
系统崩溃:数据库或操作系统故障导致进程意外终止
磁盘故障:磁盘损坏导致读取异常
自然灾害:自然灾害对数据库物理环境造成破坏
数据库恢复机制架构
场景的解释和应对策略:
- 无故障事务回滚:原子性,撤销该事务已做操作
- 故障回滚:原子性,撤销该事务已做操作
- 系统故障:原子性 持久性,已经提交的事务通过日志恢复到持久存储,未结束的事务被撤销
- 系统崩溃不能重启:持久性,一主多备
- 磁盘故障:持久性,数据多备份
- 自然灾害:持久性,异地多机容灾
存储机制应对策略
单机:
- 单个机器单个存储
- 单机数据库恢复解决:故障回滚,无故障事务回滚,系统故障
单机多数据备份:
- 但机器,多磁盘同步(避免短板,使用一致性协议:大部分完成即可)
- 解决:磁盘故障
一主多备:
- 一主机多备机,内存中的日志相互同步(日志一致保证内容一致)
- 解决:系统崩溃不能重启
异地容灾:
- 多地区不同机器,日志同步传输。
- 解决:自然灾害
对恢复快慢的评估(高可用指标)
通用高可用指标:
- 平均故障间隔时间 (MTBF, Mean Time Between Failures)
- 系统在相邻两次故障之间正常运行的平均时间。
- 平均恢复时间 (MTTR, Mean Time to Repair)
- 系统发生故障后,恢复到正常运行状态所需的平均时间。
- 平均损坏时间 (MTTF, Mean Time to Failure)
- 系统出现损坏或永久性失效的平均时间。
数据库容灾指标:
- 恢复点目标 (RPO, Recovery Point Objective)
- 系统发生故障后,能够容忍的数据丢失量,即可以恢复的最远时间点。
- 恢复时间目标 (RTO, Recovery Time Objective)
- 系统发生故障后,能够容忍的最长恢复时间,即业务中断时间。
- n个9(例如“几个九”可用性)
- 系统的可用性用n个9表示。
- 99%:一年最多不可用时间为 365 * 24 * 60 * 0.01 = 5256分钟,即87.6小时。
- 99.9%:一年最多不可用时间为 365 * 24 * 60 * 0.1% = 525.6分钟,即8.76小时。
- 系统的可用性用n个9表示。
崩溃恢复策略设计
简略说明一下崩溃恢复的情况和处理:
在系统崩溃时,事务的状态有三种:已经提交commit,abort事务,未完成的事务。
- 已提交commit:已刷脏:正确,未刷脏:重做
- 中止abort事务:已刷脏:正确,未刷脏:重做
- 未完成事务:已刷脏:回滚,未刷脏:正确
原子性保证:
NO-STEAL(非窃取):
- 未结束事务不能将脏页写入磁盘,没有原子性问题。
- 事务执行过程中不能刷新磁盘,必须占有较大的缓冲区空间,不利于多个事务的并发执行
STEAL(窃取):
- 未结束事务能将脏页写入磁盘,影响原子性,需要回滚。
- 利用Undo日志撤销事务,Undo日志记录撤销事务所需的内容
持久性保证:
Force(强制):
- 已完成事务强制将脏页写入磁盘,不存在持久性问题。
- 每次事务提交都必须刷新脏页,消耗大量IO读写资源
No-Force(非强制):
- 已完成事务不强制将脏页写入磁盘,影响持久性,需要重做。
- 利用Redo日志重做事务,Redo日志记录事务对数据库的所有影响
每种各两个选择,一共有四种选择,决定了是否有undo和redo日志
数据页面写回磁盘时机:
- 数据库关闭时,缓冲区中的所有脏页需要写回磁盘
- 缓冲区中的数据页面已经满了,如果需要继续读入数据页面,就必须将被替换的脏页写回磁盘
- 数据库会设置一个单独线程定时刷脏:全量、增量
数据库日志
日志记录是数据库活动的最小单位,每条记录反映一次操作,包含数据更新和事务的开始/结束信息。日志一旦写入磁盘便不会被修改,保证了高效的顺序写入,这为高可用恢复机制提供了基础
日志分类
按照功能:
- undo回滚日志
- redo重做日志
按照性质:
- 物理日志
- 逻辑日志
- 物理逻辑日志
Undo回滚日志
格式:<T, X, Vold>
- T:事务唯一标识符
- X:数据项
- Vold:数据项修改以前的值
当事务T修改数据项Wt(X)后产生
Redo重做日志
格式:<T, X, Vnew>
- T:事务唯一标识符
- X:数据项
- Vnew:数据项修改以前的值
当事务T修改数据项Wt(X)后产生
预写日志WAL
- 日志必须比数据更早的写入磁盘
- 日志写回磁盘的顺序必须和日志生成的时间相一致
- 对于事务原子性保证,每当页面写回磁盘时,和事务相关的undo日志需要先写回磁盘
- 对于事务持久性保证,每当事务提交的时候,和事务相关的redo日志需要先写回磁盘
日志记录方案
概念与实例
UPDATE Student SET Sname=“Mike” WHERE Sno = “1”;
- 逻辑日志:记录事务中高层抽象的逻辑操作:(UPDATE DELETE INSERT的操作文本信息)
< T’, Query=“UPDATE“, Student SET Sname = Mike WHERE Sno = 1” >
- 物理日志:记录数据库中具体物理变化:(第十个页面第100偏移量的值修改)
< T’, Table= Student, Page=99, Offset=4, Before=James, After=Mike > < T’, Index=X_PKEY, Page=45, Offset=9, Key=(1,Record1) >
- 物理逻辑日志:结合了物理日志和逻辑日志混合方法
<T’, Table= Student, Page=99, ObjectId=1, Before=James, After=Mike > < T’, Index=X_PKEY, IndexPage=45, Key=(1,Record1) >
日志性质
- 幂等性:一条日志记录执行多次和一次结果一致。例如 x = x + 1不幂等.
物理日志满足,逻辑日志不满足
- 失败可重做性:一条日志执行失败后,是否可以重做一遍达成恢复目的。插入记录时若发生故障,重做插入可以恢复数据库状态。
物理日志满足,逻辑日志不满足(插入数据成功但插入索引失败,再次执行逻辑插入可能会导致不一致)
- 操作可逆性:这是指执行某个操作后,是否可以通过逆向操作恢复到原来的状态。
物理位置不满足,逻辑日志满足(数据偏移位置可能后续被更改)
日志选择
逻辑日志不具有幂等性和失败可重做性,说明不能使用逻辑日志作为redo日志。
物理日志不具有可逆性,无法处理数据的位置变化,不能回滚。
则redo日志要用物理日志,则undo日志要用逻辑日志。
数据库恢复算法
影子拷贝方法(NO-STEAL + FORCE)
当事务开始时,系统不会直接对原始数据进行修改,而是将需要修改的数据进行拷贝,创建一个“影子副本”。再对影子副本进行一个数据修改。当事务成功完成并准备提交时,系统将影子副本更新到实际的存储中。这样,修改操作才真正生效。
缺点:效率低,难以支持事务并发,IO量大。
基于undo日志的恢复(STEAL + FORCE)
依靠undo日志完成回滚事务。
需要完成:找到所有未完成的事务 - 回滚未完成的事务 - 写入该事务中止的日志
执行流程:
- 写入日志开始记录 <T, start>
- 在修改数据项X之前,写入日志记录<T, X, Vold> (修改过的脏页允许刷盘)
- 提交事务,将关联脏页写入磁盘,将脏页相关undo日志刷盘。(页面如果被淘汰,则要与对应日志一起刷盘)
- 结束事务,如果是提交,则写入<T, commit> 如果是abort 则写入 <T, abort>
- 回滚日志,反向扫描undo日志进行回滚,将回滚中更新的脏页刷盘,写入
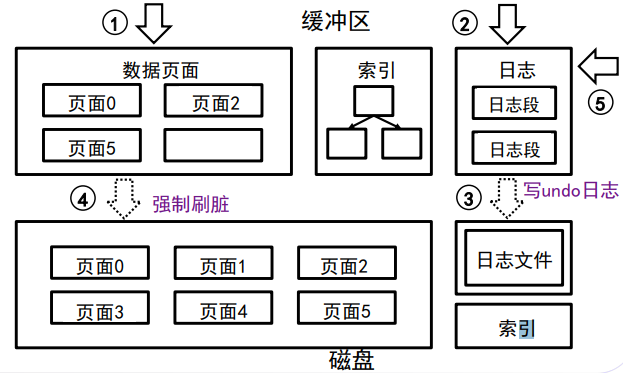
缺点:
每次事务提交都需要强制刷盘,造成随机页面读写多,性能差
难以实现主备之间同步
基于redo日志的恢复(NO-STEAL + NO-FORCE)
依靠redo日志完成回滚事务。
需要完成:找到所有已提交的事务 - 重做这些已完成的事务 - 写入该事务结束的日志
执行流程:
- 向日志中写入事务开始记录
- 在修改之前,向日志中写入redo日志记录<T, X, Vnew>(未提交事务修改过的脏页不允许刷盘)
- 提交事务,写入事务提交记录
,并且将日志刷盘。事务T关联的脏页(且该脏页无相关未提交事务)允许刷盘。 - 结束事务,如果是Abort,让缓冲区中的修改的页面失效
- 回滚事务,废弃T相关的脏页,写入中止
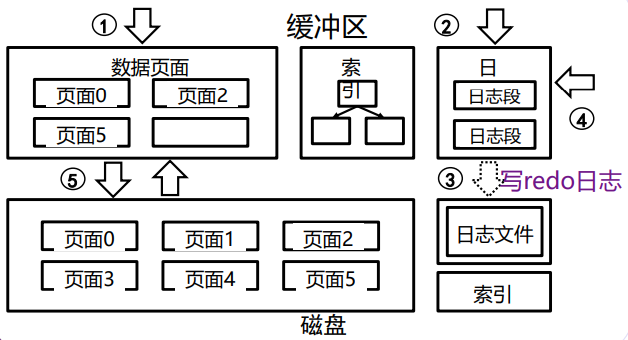
恢复流程:
- 从数据库日志末尾向前扫描日志,其中的事务T
- 如果已经出现
, 则该事务已被提交,需要重做,将数据项X置为Vnew,如果已经刷盘则不需要(通过checkpoint判断是否刷盘) - 如果出现
或者没有 提交记录,那么就不需要处理相关日志记录。 - 扫描结束后,对每个未完成的事务T,在日志中写入一个
记录并刷新日志
缺点:
事务执行期间不能刷盘,造成内存空间占用大;buffer缓冲池满时,由于不能淘汰未完成的事务,需要等待。
事务并发受限:T1修改了A并提交,T2修改了A未提交,是否允许刷盘A
基于undo/redo日志的恢复
需要依靠undo日志处理事务回滚,需要依靠redo日志处理事务重做
需要完成:找到所有需要重做以及需要回滚的事务 - 重做这些已完成的事务 - 回滚未结束的事务
执行流程:
- 向日志中写入事务开始记录
- 在修改之前,写入Undo日志和Redo日志记录<T, X, Vold, Vnew>(修改过的脏页允许刷盘)
- 提交事务:写入事务提交记录
,并且将日志刷盘,页面可不刷盘 - Abort事务:写入事务中止记录
,并且将日志刷盘,页面可不刷盘 - 回滚事务,反向扫描T相关的undo日志,执行回滚,写入该事务中止的记录
,并将日志刷盘
恢复流程:
- 分析阶段:系统从日志起始位置开始扫描整个日志,找出需要重做和需要回滚的事务
在扫描过程中出现
– 在扫描过程中出现了
- 重做阶段:系统按时间顺序正向扫描日志,如果出现了一条标注重做的日志记录,系统便重做它
重做所有日志更新记录(重放历史)
- 撤销阶段:从日志末尾反向扫描整个日志,如果出现了一条标注撤销的日志记录,那么系统会撤销它。
一旦事务撤销完成(即扫描中遇到了
由于undo日志是逻辑日志,不能多次执行一条undo日志,撤销过程中需要记录某条undo日志(补偿日志)是否被执行过。
- 补偿日志:Undo日志的redo日志
每次执行undo日志记录后,数据库需要向日志中写入一条补偿日志记录(compensation log record,CLR),记录撤销的动作
CLR实现了undo日志的redo,记录已经undo的日志,保证undo不被重复执行
检查点CheckPoint机制
检查点的使用方法:
- 在检查点之前完成(commit/abort)的事务不需要处理
- 在检查点之后commit/abort的事务需要重做;
- 所有未完成的事务(不含commit/abort)需要回滚。
检查点的记录方法:
- 停止接受新的事务或修改请求,确保没有新的脏数据产生。
- 将当前所有未持久化的脏数据页写入磁盘,更新对应的数据文件。
- 记录检查点位置。
- 恢复接受新的事务或修改请求,继续正常的数据库操作
