这篇文章上次修改于 333 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
输入是物理执行计划,由优化器产生并给予,输出代码或者机器码。
发展过程
- 1994:火山模型(尽量减少内存)
- 2000:物化模型
- 2005:向量化执行
- 2010:源到源编译模型
- 2011:实时编译模型HYPER
执行器概述
拉取式模型与推送式模型
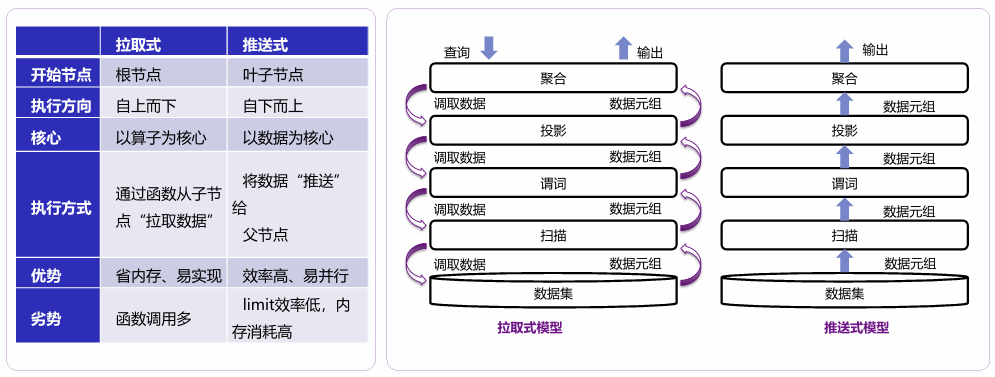
拉取式模型
拉取式模型从根节点往下调用数据,可以使用以下模型:
- open():初始化,申请空间,设置连接
- getNext():获取符合当前节点条件的下一条记录
- colse():清理
对于一个树中节点的getNext(),通过获取子节点的getNext即可获得自己接收的数据集合,再将通过本节点条件的数据返回,如果没有数据,即代表结束。
火山模型
一次一个元组
火山模型(volcano model)又被称为迭代模型(iterator model)或流水线模型(pipeline model)。类似于迭代操作一样,每个节点都在不断迭代自己要处理的数据行,也类似与流水线一样,每行数据从下往上给出。
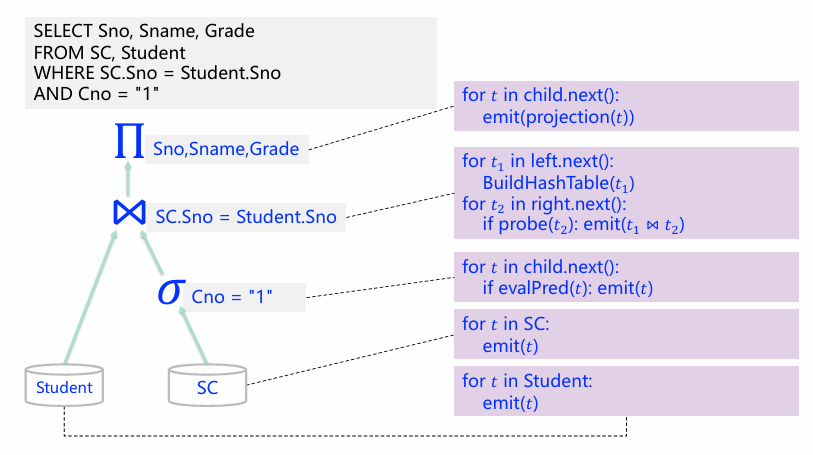
以上给出了每个节点的next操作,从执行最上面的next即可运行完整一个计划执行树
物化模型
算子会将所有输入处理好后,将处理完的所有结果一次性输出。输出既可以是完整的元组,也可以只包含其中部分的列。
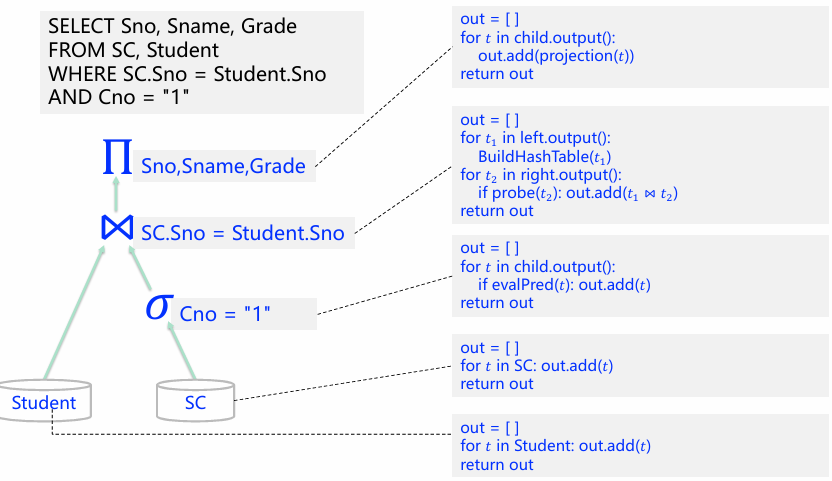
以上给出了每个节点的next部分,不同火山模型的是,不再有多次递归,而是把本节点所有的符合条件的元组集合返回回去。
向量化执行模型
向量化执行模型(Vectorization Model)可以在一定程度上被视为火山模型与物化模型的中间形态。
通过next()函数自上而下地拉取数据,每次会拉取一个批次的元组数据,而不是只有一个。
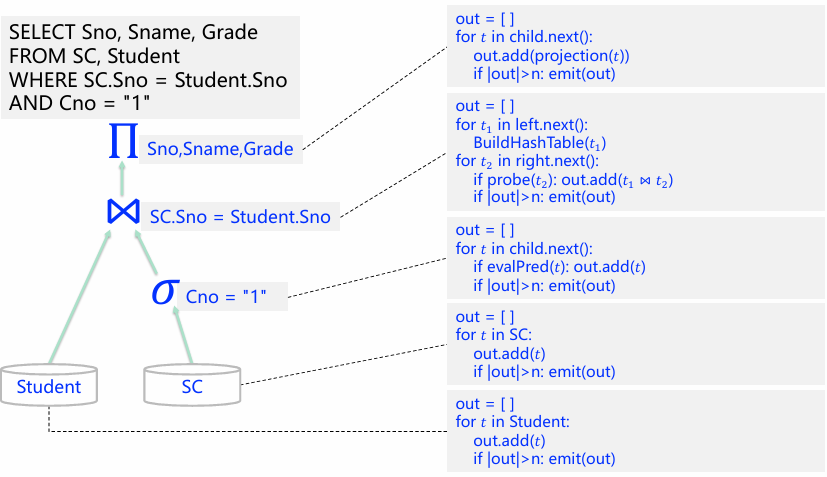
以上给出了每个节点的next部分,与火山模型不同的是,每次返回的数据不是一条,但与物化模型不同的是,并不是每次都返回所有的数据,而是一部分,即将一条改为一块,至于块数据大小由n决定。
模型比较
火山模型更消耗递归成本,而物化模型更消耗缓存成本,向量化执行模型是两者的中间态。
| 函数调用 | 火山 | 物化 | 向量化 |
|---|---|---|---|
| 流水线 | 多 | 少 | 中 |
| 内存 | 好 | 无 | 中 |
| 适用场景 | OLTP | OLTP | OLAP |
| 代码局部性 | 差 | 好 | 中 |
| 数据局部性 | 中 | 好 | 好 |
| 实现难度 | 简单 | 中 | 难 |
推送式模型 Push-based
自底向上运行,
遇到汇聚节点(连接,哈希,排序,分组)需要需要分解为不同的pipeline
Pipeline之间需要调度:并行或者先后依赖。
每个Pipeline自底向上执行
Pipeline分解
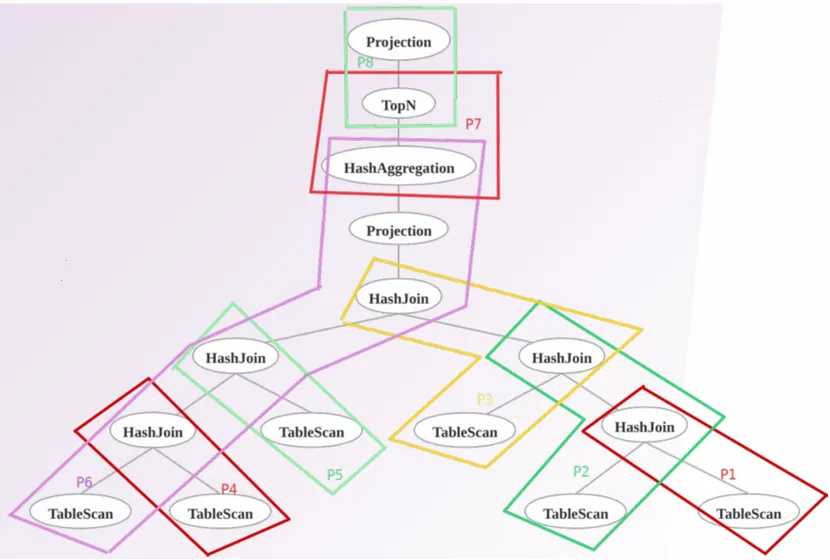
以上是一个Pipeline分解,有以下步骤:
- 枚举算子
- 找到sink节点(连接,哈希,排序,分组)
- 根据sink节点生成pipeline
- 确定pipeline的先后关系
Pipeline调度
事件驱动的调度器使用生产者消费者的线程池模型,根据任务队列和父子pipline之间的依赖关系进行调度。
每类节点的执行状态有四种:Have_more_output,Need_more_input,Finished,Blocked
优点
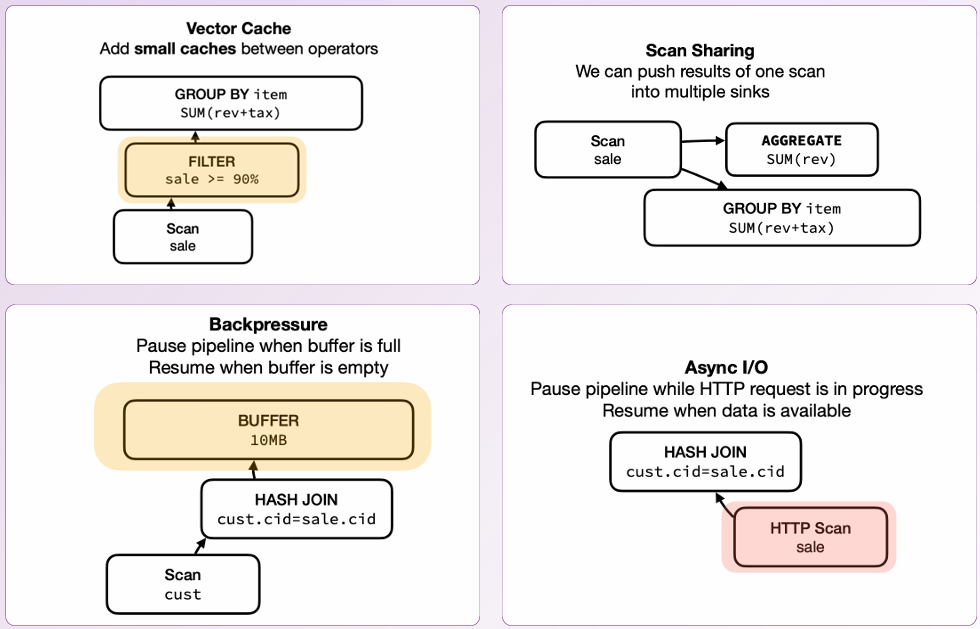
- Vector Cache: 通过在操作符之间添加小缓存,可以减少数据重复扫描,提高查询效率,特别是在处理重复或相似查询时。
- Scan Sharing: 允许将一次扫描的结果推送到多个接收端,减少重复扫描的开销,提升整体系统性能,尤其是在多个操作需要相同数据时。
- Backpressure: 当缓冲区满时暂停管道,防止系统过载,确保数据处理稳定性和资源有效利用,避免数据丢失或系统崩溃。
- Async I/O: 在HTTP请求进行时暂停管道,等待数据可用时再恢复,提高系统响应性和资源利用率,特别是在处理外部数据源时。
推送式模型比较
| 拉取式 | 推送式 | |
|---|---|---|
| 开始节点 | 根节点 | 叶子节点 |
| 执行方向 | 自上而下 | 自下而上 |
| 核心 | 以算子为核心 | 以数据为核心 |
| 执行方式 | 通过函数从子节点“拉取数据” | 将数据“推送”给父节点 |
| 优势 | 易实现、优雅、省内存 | 函数调用少、缓存命中率高、效率高 |
| 劣势 | 函数调用多、缓存命中率低 | Limit, sort-merge join效率低,内存消耗高 |
并行执行
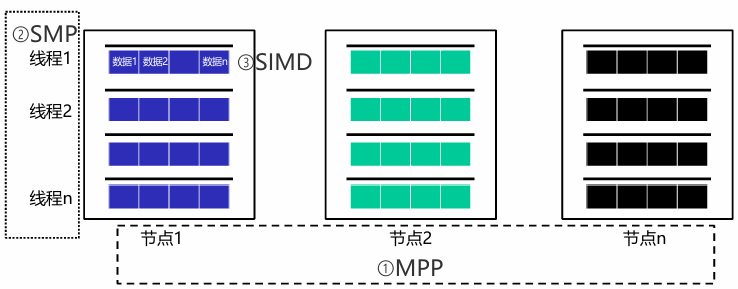
- 节点间多机器并行 MPP:Massively Parallel Processing
- 节点内多线程并行 SMP:Symmetric Multi-Processing
- 单指令多数据并行 SIMD:Single Instruction Multiple Data
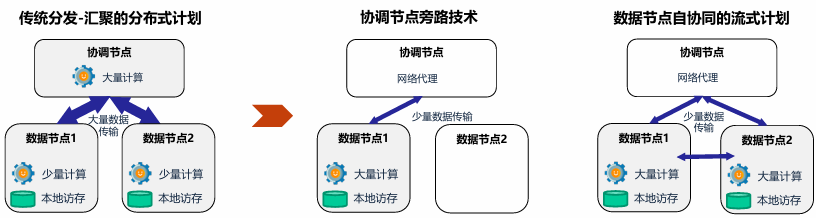
节点间多机器并行 MPP
- 传统分发-汇聚的分布式计划
- 协调节点旁路技术
- 数据节点自协同的流式计划
节点内多线程并行 SMP
- 算子间并行:计划切分,流水线
- 算子内并行: 数据分区
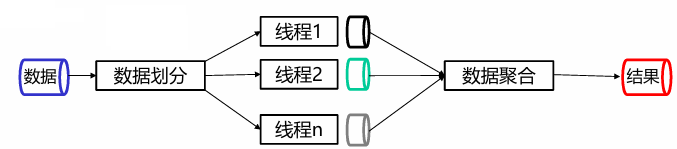
单指令流多数据 SIMD
是一种允许同一个处理器在多个数据点上执行相同操作,进而形成并行计算的技术。

编译执行
- 通过编译执行技术避免大量虚函数调用,并裁剪了大量执行中的分支判断等指令,减少了无用指令数量。
- 在火山模型中,每次获取数据都需要访问一次内存,编译执行避免迭代调用过程,通过多级存储和预取技术将数据缓存在CPU,提升了缓存命中率
- 循环展开和优化,通过流水线和指令重排序技术,提升了循环的运行效率。
有两种编译执行方法:
- 查询执行计划 → 高级语言代码(例如C)→ 可执行代码 [代价高]
- 查询执行计划 → 中间表示IR(LLVM)→ 可执行代码
LLVM
- 模组化的架构,允许所有人对它进行改进
- 后端允许将IR转换为不同CPU架构上的机器码
- 前端允许将不同代码转换为IR
- IR会不断地自我优化,直到达到最优解
LLVM编译执行
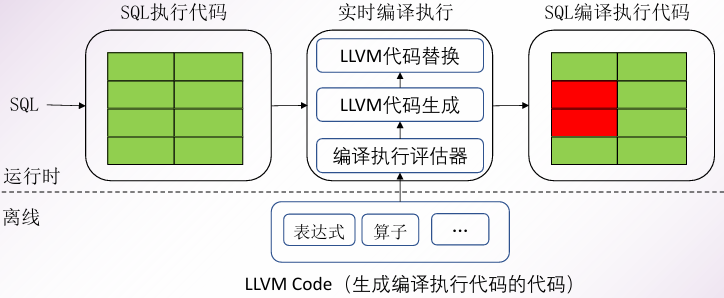
预先编译与实时编译
预先编译是指在程序运行之前进行编译。其优点在于可以提前将代码编译好,这样在实际运行时就可以省去编译时间,并且可以快速启动并达到较高的性能
实时编译是在程序运行中编译而不是之前。许多高级编程语言中存在定义不明确的情况,因此在合适的时机进行编译可以有效避免计算资源或存储资源的浪费。
实时编译的优势:
- 避免不必要的判断步骤
- 优化表达式的计算
- 优化执行流程:在获取到查询计划之后,数据库就可以根据查询计划针对性地设计执行流程,使元组尽可能长的留存在寄存器中。
拓展了解:源到源编译模型HIQUE,实时编译模型HYPER
