这篇文章上次修改于 604 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
数据库管理系统——数据库储存引擎
存储概览
SQL引擎 —— 执行器 —— 存储引擎 —— 存储介质
存储引擎:文件组织 页面组织 元数据 日志 索引 缓冲区 故障恢复 并发控制
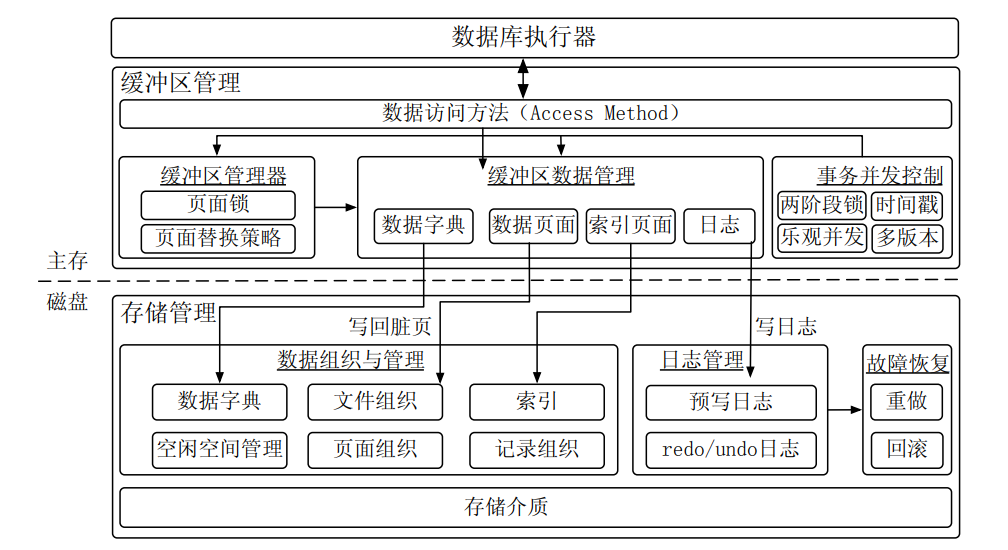
对于把数据放在磁盘中,直接写入会导致并发的效果很差。因此引入页面的概念。
把文件分成很多个页面,把数据放在页面中,页面大小固定,通常是(4K, 8K, 16K)。每次插入时,找到有空闲空间的页面,涉及到了空闲空间管理。
记录指的是一行表中的数据,如何查找记录,就涉及到记录组织。 索引在数据库系统中是用于提高查询操作的效率,使得对表中数据的查找、检索更加快速。
数据字典是数据库系统中的一个重要组件,用于存储和管理关于数据库结构和元数据的信息。它包含了数据库中所有表、索引、视图、存储过程、触发器、权限等对象的定义和描述。
缓冲区管理了数据字典,数据页面,索引页面,日志以确保高效数据传输。一旦发生丢失,就需要通过日志进行回滚和重做。
对于缓冲区的页面管理,当我用到一个页面不在缓冲区,我就去从磁盘读取,如果缓冲区空间不足,就把一些页面从缓存淘汰出去。
对于写入到磁盘,通常是异步的写入,项数据字典,数据页面,索引页面等,会需要从内存写入到磁盘。
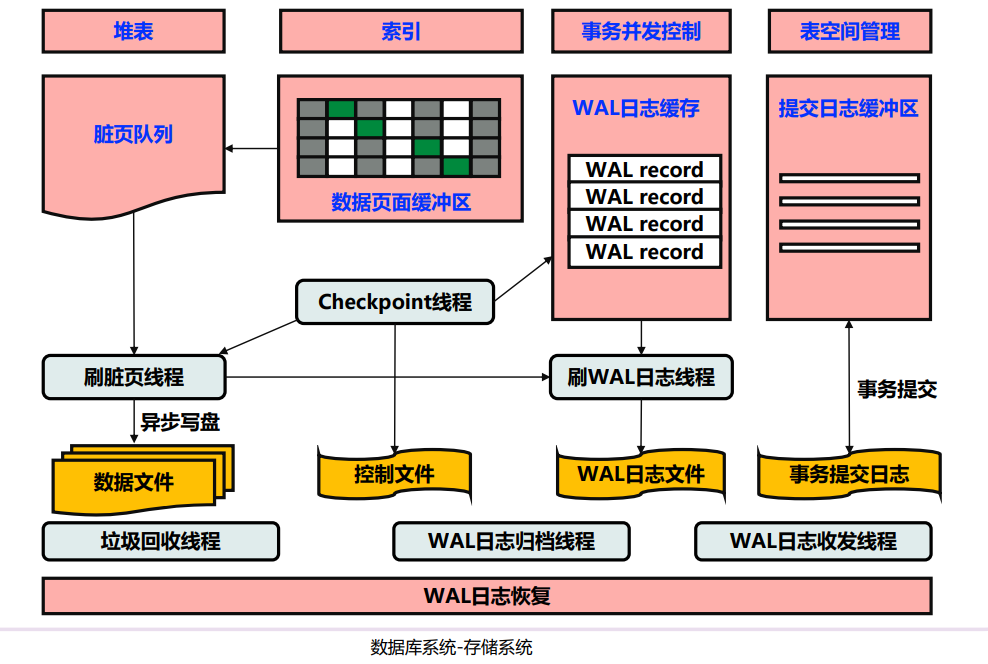
堆表是数据库中一种没有聚簇索引的表,数据记录以无序的方式存储在物理磁盘上。堆表是一种最简单的表存储方式,每当有新的数据插入时,它直接将记录放在第一个可用的空闲位置,而不按照特定顺序排列数据。
脏页指的是在内存中的页被更新,但是还没写到磁盘当中。脏页游一定的队列,异步地刷入磁盘。
Checkpoint 是数据库系统中的一种机制。记录了数据库在某个时间点上数据的一致性状态。这个时间点之前的所有更改已经从内存(缓冲区)同步到磁盘,并且这些更改不再依赖WAL日志来恢复数据。
WAL(Write-Ahead Logging,预写日志) 是一种数据库恢复机制,确保在将数据实际写入磁盘之前,先把对数据的修改写入日志文件中。WAL日志可以确保即使系统崩溃,数据库也能通过重放日志恢复到一致的状态。
数据组织
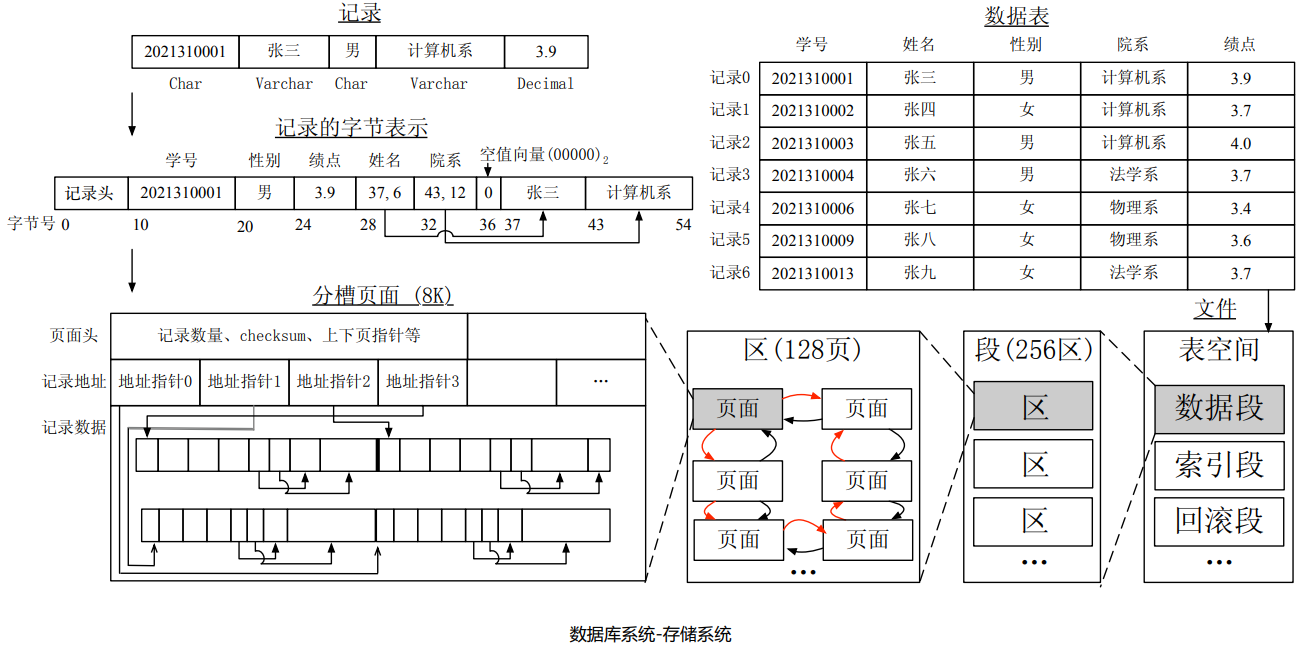
当插入一个记录,会去申请数据的内存,但是一次申请一个页面的效率太低,因此一次性申请1段 = 256 区,其中 1 区 = 128 页。同时,还可以确保这些页面或者说区是连续的,确保读写效率。
记录不仅有数据量,还有数据属性。要把数据属性,数据量,放入页面中,对于页面,甚至还分槽,一个槽来负责一个记录。
页面组织
元组管理和追加日志管理(元组管理写改速度均衡,追加日志管理写快改慢)
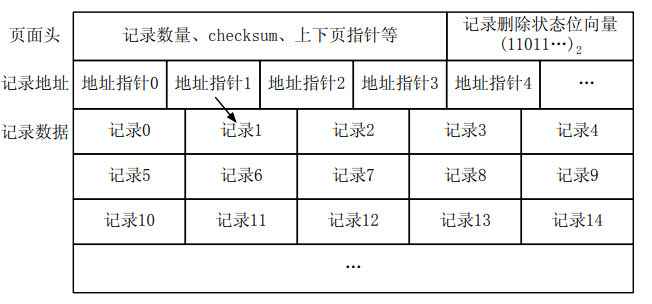
页面头:
- 记录数量:record的个数
- checksum:校验和,用于判断页面的内容是否正确,防止读写错误
- 上下页指针:上一页的指针和下一页的指针
对于表中的空值NULL,为了避免占用空间,可以选择使用空值向量,可以确定记录中每个位置是否是空值。
定长记录
长度固定,页面中记录数目固定,易于定位。
记录组织:
- 记录头:事务信息、NULL值bitmap
- 每个属性值
页面组织:
页面头:
- 记录数量
- Checksum:防止读写错误
- 上下页面指针(PageID)
- 页面在文件的offset(由于定长,所以知道对应的offset或者第几页就可以快速定位)
- 页面类型:索引、数据
- 空闲空间(Bitmap)
记录内容
对于空闲空间管理,使用页面头中的空闲空间Bitmap,记录了每个槽位的空闲情况,如果一条记录被删除,就记录这个位置为空闲。因此有以下操作
- Insert插入:找到第一个空槽
- Delete删除:清楚槽标志位
- Bitmap数目根据页面大小和记录长度计算
变长记录
记录中的变长属性通过偏移量和长度定位
对于页面内如何保存记录,由于记录是变长的,所以我们不妨用槽位的概念,把记录定义为一个槽位,槽位有两个值的属性:偏移和长度(起始地点和槽位大小)。槽位属性值是固定大小的,因此它可以像定长一样储存在页面中,然而槽位本身是变长的,两者要互不干扰,我们就让槽位属性放在前面,槽位放在页面后面。
同时对于空闲空间,我们不能再用bitmap来表示,因为能塞多少条我们是不知道的。
但对于前塞属性后塞内容,中间的那一块是空闲的,我们称作剩余空间。剩余空间的起点是容易得到的(属性值的最后),终点就需要在页面头当中记录了。
变长记录组织
- 记录头:事务信息、NULL值bitmap
- 属性槽位:起始位置和长度
页面内记录组织
- 页面头:页类型、状态
- 槽位:记录起始地址、长度(索引会指向槽位)
- 两头挤:页面、槽位等页面内从前往后;记录从后往前
对于插入,就直接在空余空间中塞入即可。但是对于删除,有两个阶段。当删除时,删除对应的记录属性即可,在删除了一定的量之后,页面会重新排布空间,把剩余空间再次腾空在中间位置。
页面组织思考
如何处理记录长度大于页面大小?
- 记录跨页链接
- 专门存储方式
如何处理一条记录有很多NULL值?
- 利用bitmap对NULL值进行压缩
文件组织
1. 堆表
- 定义:堆表是一种无序的数据存储方式,数据以随机的方式插入到页面中。每个数据页面中的记录按照插入的顺序存储,没有特定的顺序。
堆表的多级空闲空间数组
快速找到空闲空间的位置, 从高到低扫描各级空闲空间数组(也可以用大根堆替代空闲空间数组,维护各页面空闲空间比例)
-
特点:
插入效率高,查找效率低,删除复杂
2. 顺序表
-
定义:顺序表是一种有序的数据存储方式,数据按照某一列(通常是主键或索引列)进行排序。
-
特点:
查找效率高,插入和删除复杂
3. 哈希表
-
定义:哈希表通过哈希函数将键值映射到固定大小的数组中,以实现快速访问。
-
特点:
查找效率高,插入和删除效率高
限制:哈希表适用于点查找,但对于范围查询不太合适,因为数据不是有序的。
4. B+树
-
定义:B+树是一种自平衡的树数据结构,用于实现动态集合的高效存储和查找。B+树的所有值都存储在叶子节点中,内节点仅存储索引信息。
-
特点:
高效的查找、插入和删除,支持范围查询,适合磁盘存储
空闲空间管理
- 插入一条长为x的记录,应该插入到哪个页面?
- 堆表需要找到合适的页面(空闲空间大于x的页面)
- 记录每个页面空间空间大小
- 利用倒排列表
示例说明:
有页面有足够空闲大小
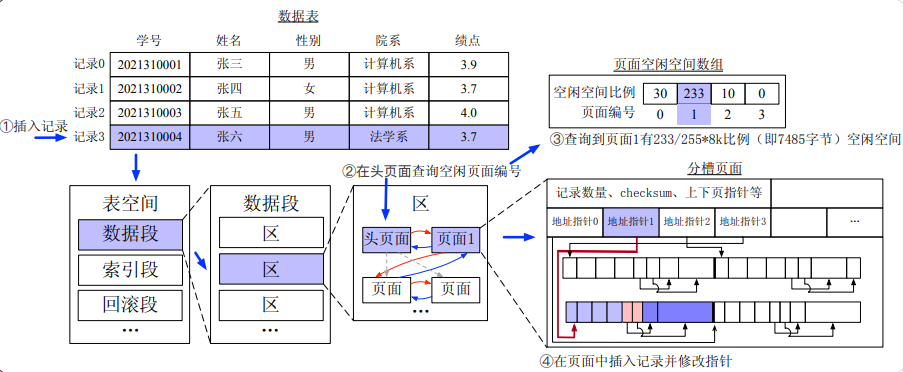
(如果无空闲记录,就需要创建申请新的区)
查询记录(有索引)
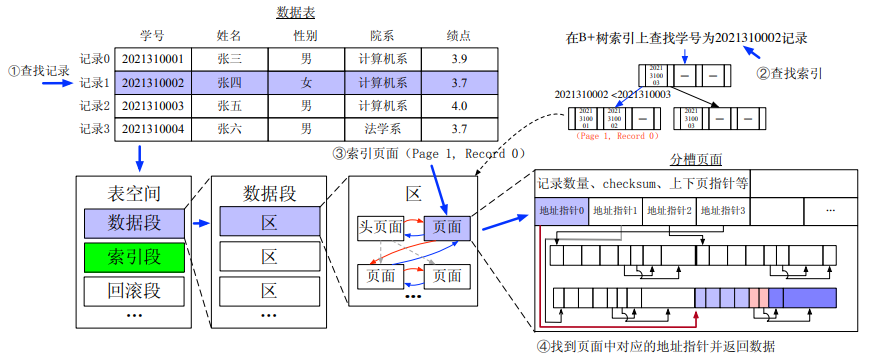
(无索引就遍历每个页面)
删除和更新记录
删除一条记录:首先查找到该条记录,然后删除
- 定长:bitmap置为0
- 变长:槽位清零
更新一条记录:首先查找到该条记录,然后更新
- 定长:直接可以原位更新
- 变长: 如果新纪录不长于老记录,原位更新,更新槽位 如果新纪录长于老记录,槽位清零,插入新纪录 (若本页面可以容纳,则插入本页面,若本页面不可以容纳,则插入其他页面)
元数据存储
关系表本身的属性
- 表名,即关系表名称
- 列名,即关系表的属性名
- 属性的域和长度
- 视图的名称和定义
- 完整性约束,例如外键约束
- 关系表的属性的统计信息,可用于辅助查询优化
- 索引信息
实际上就是多个表,和关系表一样储存即可。
缓冲区
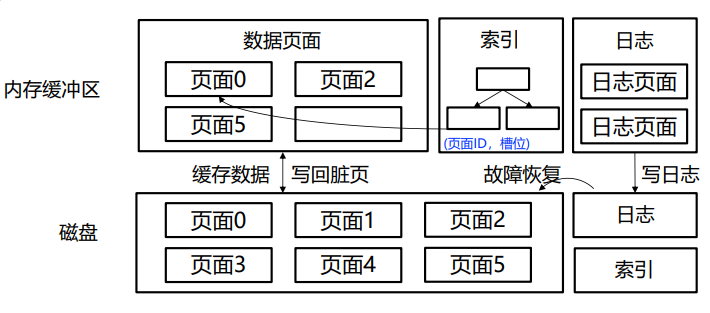
- 更新缓冲区页面
- 更新缓冲区索引
- 更新缓冲区日志
- 更新磁盘日志
- 返回提交成功
- 异步刷新数据和索引页面
当程序请求访问磁盘页面时
- 如果该页面已经在缓冲区中,则返回缓冲区中的页面数据
- 如果该页面不在缓冲区中,则从磁盘上读取该页面:
如果缓冲区未满,则将数据写入缓冲区
如果缓冲区已满,则根据缓冲区页面替换策略挑选其他页面剔除或写回到磁盘上,再读入新页面
(日志页面也是同理的)
缓冲区页面固定和锁
当一个进程正在读取或写入某个页面时,该页面不应该被剔除,否则会读取或写入错误的数据
- 因此需要将使用中的页面暂时固定住(pin)
- 共享锁(shared locks):使多个进程可同时读取页面
- 和排他锁(exclusive locks):保证一个进程在修改页面时其他进程不可访问页面
缓冲区页面替换策略
- 最近最少使用策略LRU:前1次使用时间越晚(越近期)的页面将来越有机会被使用,越不应该 被替换
- 最不经常使用策略LFU:使用频率越高的页面将来越有机会被使用,越不应该被替换
- LRU-K策略:前第K次访问的时间越晚的页面将来越有机会被使用,越不应该被替换
行存储和列存储
行存储
适合数据增删改
优点:
- 数据被保存在一起
- 插入和更新速度快
缺点:
- 选择操作时即使只涉及某几列,所有数据也都会被读取
使用场景:
- 点查询(返回记录少,基于索引的简单查询)
- 增、删、改操作较多的场景
列存储
提高数据分析查询的速度;提升数据压缩率
优点:
- 查询操作时只有涉及的列会被读取
- 投影操作很高效
- 易于压缩
缺点:
- 选择操作完成时,被选择的列要重新组装
- 插入和更新速度慢
使用场景:
- 统计分析类查询(关联、分组操作较多的场景)
- 即席查询(用户灵活自定义条件,查询条件不确定,行存表扫描难以使用索引)
行列转换
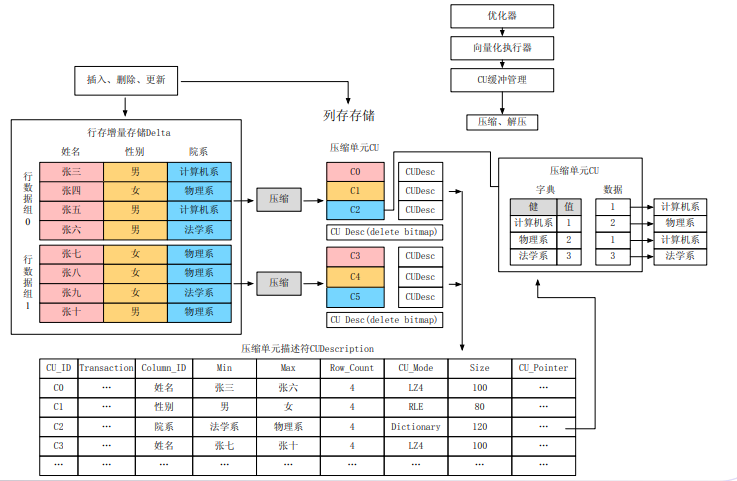
先按照行插入删除更新,等到固定下来后,对行数据组进行分组压缩,转换成列储存进行保存插入。
