这篇文章上次修改于 1408 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
虽然听起来十分高级,但是说清楚了,网络爬虫就是在机器代替人的时代下,让机器代替人上网,从网上获取信息,让程序服务人来获取网上数据,网上操作,这就是网络爬虫。
做一个网络爬虫,我们要先了解http协议和tcp协议,
HTTP协议
HTTP简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
在如此抽象的概念之下我们需要一些基础的理解,后端,前端,浏览器,用户之间的关系。
简单说,就是用户利用浏览器。浏览器作为用户和网站交流的中介,他可以理解服务器返回的数据,并对其加以处理
举一个例子(这是一个返回的html文件)
<html>
<head>
<title>我的第一个 HTML 页面</title>
</head>
<body>
<p>body 元素的内容会显示在浏览器中。</p>
<p>title 元素的内容会显示在浏览器的标题栏中。</p>
</body>
</html>
在浏览器的处理下,会变为
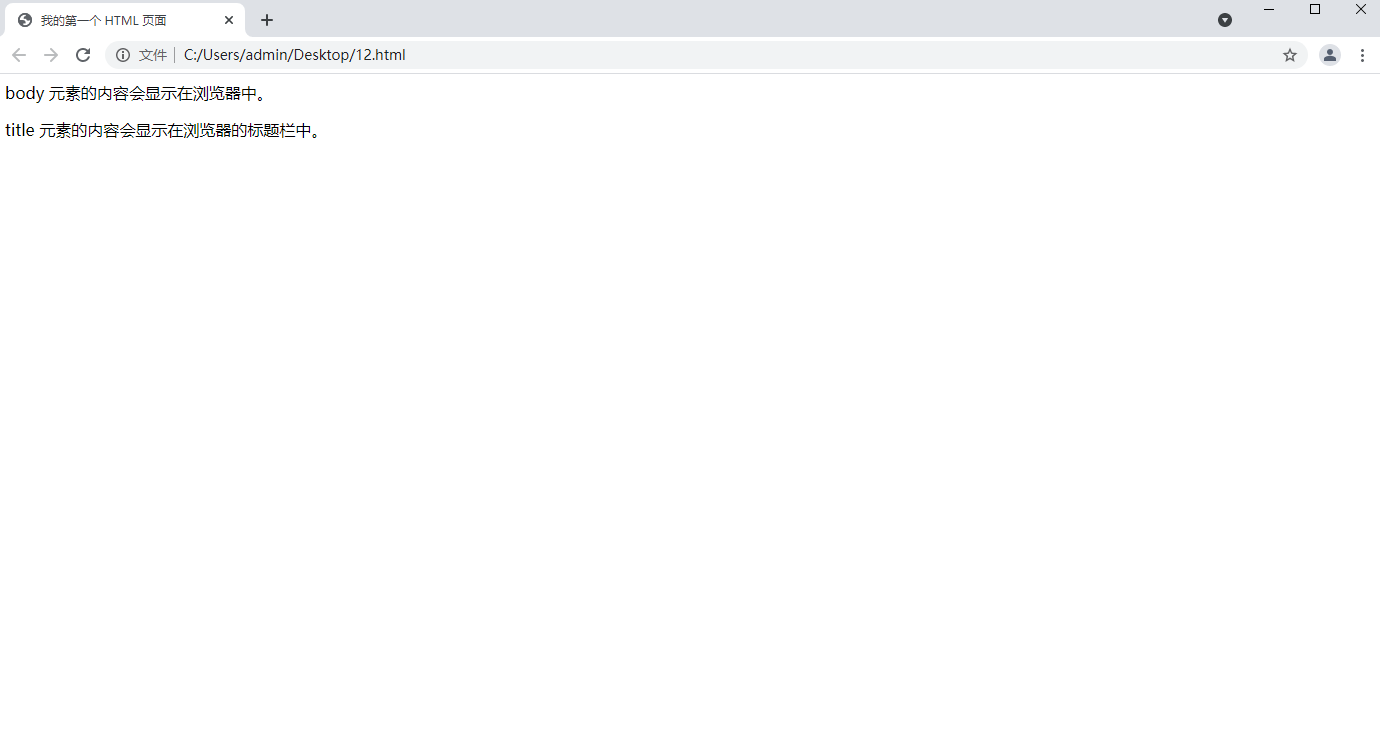
这就是用户通过浏览器看到的页面
他的内部可以置入许多按钮和输入框,这样的话,用户可以根据需要,就比如登录,就要通过输入账号密码
这个时候,用户就是在前端进行操作(前端就是指上面返回的页面,高级的前端会有很多脚本,可以供用户提交表单)
前端提交的数据交给后端,后端对提交的数据包进行处理,忽略和排除非法的包(
后端会再次返回数据交给前端
前端再次分析显示数据,用户看到的画面就会变化
在这个过程中,如果我们要做网络爬虫,我们就要从对后端发送数据包开始
这个时候我们要通过"抓包"操作,对前端发送的数据包进行分析,了解发送的数据包的规律和参数分布
模仿用户对前端的操作,发送数据包给后端,从后端返回的数据里面,找到自己需要的进行过滤
HTTP消息结构
以下是一个header
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi这只是一些基础的参数
但对于post,我们是要传参的,会比上面那个多几个参数(部分get也会有),例如
| Header参数 | 分类描述 | 示例 |
|---|---|---|
| Authorization | 信息,服务器收到请求,需要请求者继续执行操作 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Referer | 先前网页的地址,当前请求网页紧随其后,即来路 | Referer: https://www.baidu.com/ |
| Content-Length | 请求的内容长度 | Content-Length: 233 |
| Content-Type | 请求的与实体对应的MIME信息 | Content-Type: application/x-www-form-urlencoded |
| Host | 指定请求的服务器的域名和端口号 | Host: www.baidu.com |
| Cookie | HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。 | Cookie: $Version=1; Skin=new; |
HTTP 协议中共定义了八种方法或者叫“动作”来表明对 Request-URI 指定的资源的不同操作方式,具体介绍如下:
- OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送’*'的请求来测试服务器的功能性。
- HEAD:向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
- GET:向特定的资源发出请求。
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
- PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除 Request-URI 所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
虽然 HTTP 的请求方式有 8 种,但是我们在实际应用中常用的也就是 get 和 post,其他请求方式也都可以通过这两种方式间接的来实现。
但至于我们只要做低级爬虫
只要了解这两个就已经足够了
- GET:请求指定的页面信息,并返回实体主体。
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
HTTP状态码分类
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
HTTP状态码分类
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
HTTP状态码列表:
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
中华万年历爬虫示例
简介
中华万年历—让时光充满乐趣,日历类TOP 1应用。基于传统黄历、日程记录等日历功能上提供个性化阅读服务、生活提醒服务等,致力于成为用户的智能生活提醒助手 。
那我们可以从它这里获取什么呢?
天气是中华万年历可以提供的,所以我们的目标是获取天气,这样子的话,我们就可以不用天天跑网站上看天气了(好像也没什么很大必要,由于是练习,就依我这么说罢)
我们要先找到获取天气的地方,进行‘抓包’
抓包
抓包工具有许多,像fiddler,Charles,还有许多浏览器自带的开发者模式(例如谷歌的F12)等等
对于我们来说,浏览器的代理就够用了,不过我这里依然拿Charles做示例,软件的使用方式请自行查询
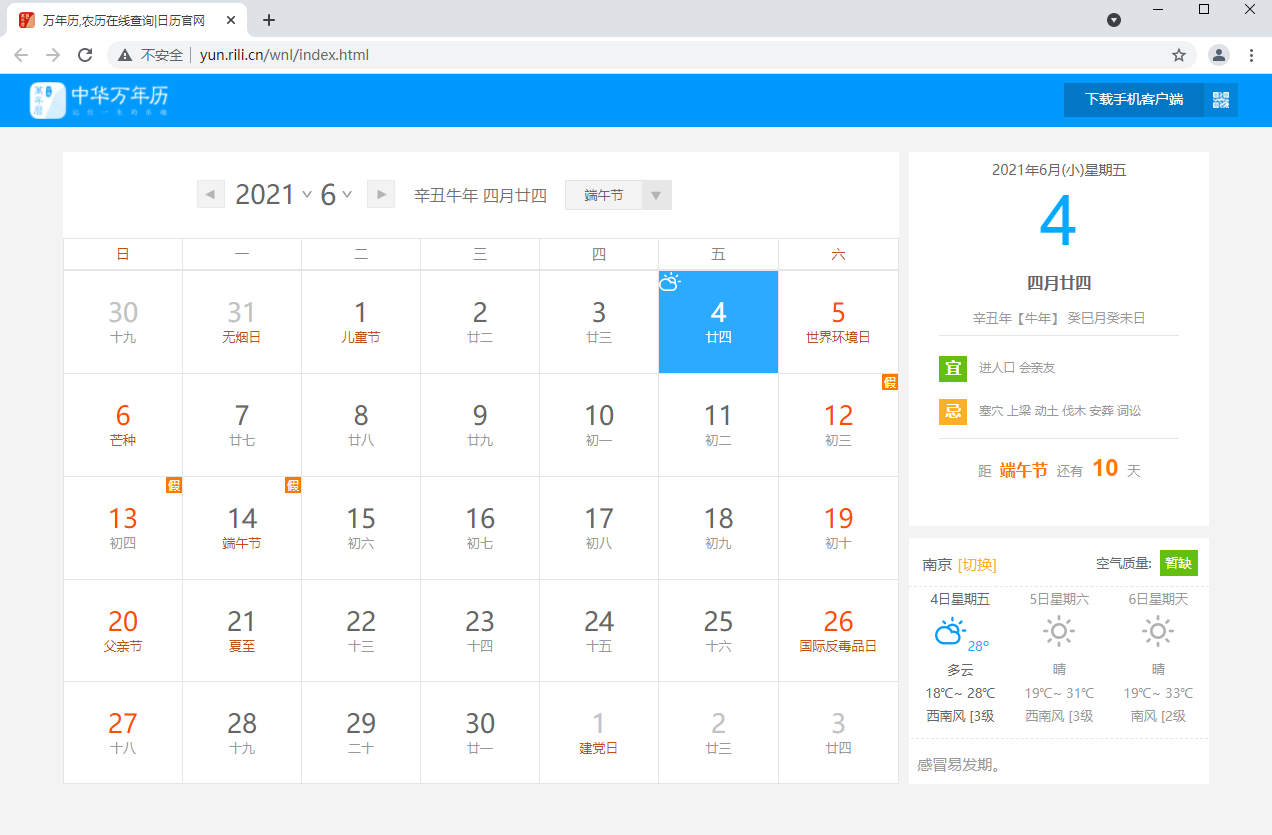
找到这个页面之后,我们发现,它可以显示出天气,说明后端在前端的请求中返回了关于天气的数据
此时利用抓包工具我们能发现这些数据
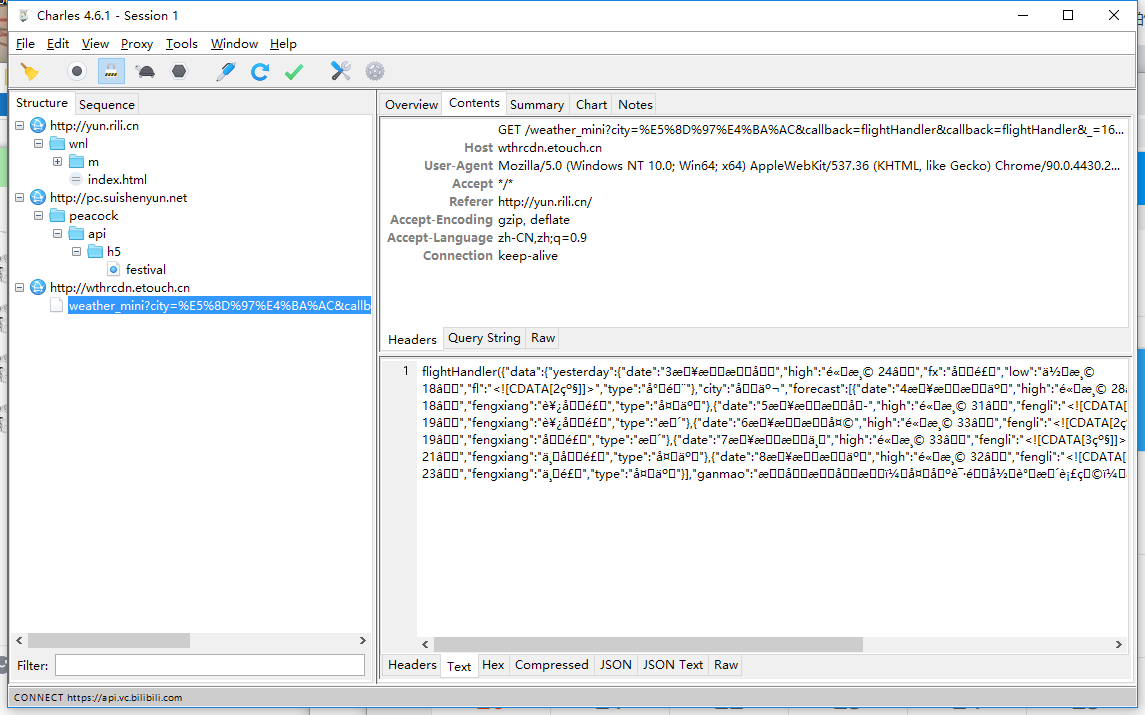
这里我们发现了一个问题,就是返回的数据不能正常显示,其实就是被加密了。我们可以在accept-encoding中发现gzip,代表了后端返回的数据是经过gzip加密的,不过问题不大,如果感兴趣的话,可以自行查询和研究,python的requests库内的请求是会自动根据返回值进行解码的
不过这里就先跳过了,
再来观察参数,我们是get方式获取数据的,所以参数都在url(网址之中)我们来观察网址后缀
/weather_mini?city=%E5%8D%97%E4%BA%AC&callback=flightHandler&callback=flightHandler&_=1622798035220
问号之后就是我们需要观察的参数
(你可以想象一下我写了5000多字文章没保存现在只有3500留下来的感受)
(插播:请大家随时按ctrl+s)
这里我们发现一段尤其显眼的东西“%E5%8D%97%E4%BA%AC”这里其实是中文的url编码,大致意思就是中文在网址里面的编码,通过url解码,我们可以得到结果“南京”所以在city参数后面的值就是“南京”。
所以我们可以大胆猜测一下网址就是查询的方式。
http://wthrcdn.etouch.cn/weather_mini?city=北京
http://wthrcdn.etouch.cn/weather_mini?city=温州
http://wthrcdn.etouch.cn/weather_mini?city=曹县选择一个用python的requests库进行获取
import json
import requests
a = requests.get('http://wthrcdn.etouch.cn/weather_mini?city=乐清')
res_json = json.loads(a.text)
print(res_json)输出结果
{'data': {'yesterday': {'date': '20日星期日', 'high': '高温 25℃', 'fx': '东北风', 'low': '低温 22℃', 'fl': '<![CDATA[2级]]>', 'type': '中雨'}, 'city': '乐清', 'forecast': [{'date': '21日星期一', 'high': '高温 25℃', 'fengli': '<![CDATA[2级]]>', 'low': '低温 20℃', 'fengxiang': '东北风', 'type': '小雨'}, {'date': '22日星期二', 'high': '高温 28℃', 'fengli': '<![CDATA[2级]]>', 'low': '低温 22℃', 'fengxiang': '北风', 'type': '小雨'}, {'date': '23日星期三', 'high': '高温 27℃', 'fengli': '<![CDATA[2级]]>', 'low': '低温 23℃', 'fengxiang': '东北风', 'type': '多云'}, {'date': '24日星期四', 'high': '高温 27℃', 'fengli': '<![CDATA[1级]]>', 'low': '低温 22℃', 'fengxiang': '东风', 'type': '多云'}, {'date': '25日星期五', 'high': '高温 27℃', 'fengli': '<![CDATA[1级]]>', 'low': '低温 24℃', 'fengxiang': '东南风', 'type': '小雨'}], 'ganmao': '感冒低发期,天气舒适,请注意多吃蔬菜水果,多喝水哦。', 'wendu': '23'}, 'status': 1000, 'desc': 'OK'}分析
数据看起来杂乱无章,实际条理很有序,经过json格式化
{
"data": {
"yesterday": {
"date": "20日星期日",
"high": "高温 25℃",
"fx": "东北风",
"low": "低温 22℃",
"fl": "<![CDATA[2级]]>",
"type": "中雨"
},
"city": "乐清",
"forecast": [
{
"date": "21日星期一",
"high": "高温 25℃",
"fengli": "<![CDATA[2级]]>",
"low": "低温 20℃",
"fengxiang": "东北风",
"type": "小雨"
},
{
"date": "22日星期二",
"high": "高温 28℃",
"fengli": "<![CDATA[2级]]>",
"low": "低温 22℃",
"fengxiang": "北风",
"type": "小雨"
},
{
"date": "23日星期三",
"high": "高温 27℃",
"fengli": "<![CDATA[2级]]>",
"low": "低温 23℃",
"fengxiang": "东北风",
"type": "多云"
},
{
"date": "24日星期四",
"high": "高温 27℃",
"fengli": "<![CDATA[1级]]>",
"low": "低温 22℃",
"fengxiang": "东风",
"type": "多云"
},
{
"date": "25日星期五",
"high": "高温 27℃",
"fengli": "<![CDATA[1级]]>",
"low": "低温 24℃",
"fengxiang": "东南风",
"type": "小雨"
}
],
"ganmao": "感冒低发期,天气舒适,请注意多吃蔬菜水果,多喝水哦。",
"wendu": "23"
},
"status": 1000,
"desc": "OK"
}结果嵌套分明,我们可以通过res_json = json.loads(a.text)来把获取到的数据转换成dict,以便我们进行访问,经过数据处理,我们可以轻松获取其中的数据
print(res_json['data']['yesterday']['date']) # '20日星期日'
print(res_json['data']['city']) # '乐清'
print(res_json['data']['forecast'][0]['date']) # '21日星期一'我们成功的完成了我们的爬虫任务,那现在可以做什么呢?,这里给出示例
import requests
import json
import datetime
import re
import time
from PIL import Image, ImageDraw, ImageFont
class WeatherApi(object):
def __init__(self):
self.url = 'http://wthrcdn.etouch.cn/weather_mini?city='
self.ttf_path = '..\\Requirement\\font\\simhei.ttf'
def get_weather(self, location):
request_url = self.url + str(location)
back_data = requests.get(request_url)
json_weather = json.loads(back_data.text)
return json_weather['data']
def process_data(self):
json_weather = self.get_weather('上海')['data']
tips = json_weather['ganmao']
temperature_now = json_weather['wendu']
weather_forecast = json_weather['forecast']
# m = re.findall("\d+", weather_forecast[1]['high'])[0]
return tips, temperature_now, weather_forecast
def img_crate(self, json_weather):
column = 1
back_ground = Image.open('..\\Requirement\\background\\weather\\dark.png')
data_today = json_weather["forecast"][0]
day_type = data_today['type']
if day_type == '晴' or day_type == '多云':
back_ground = Image.open('..\\Requirement\\background\\weather\\bright.png')
month = datetime.datetime.now().month
img_draw = ImageDraw.Draw(back_ground)
for i in range(1, 5):
data = json_weather["forecast"][i]
week = '周' + data['date'][-1]
date = re.findall(r'\d+日', data['date'])[0]
if int(re.findall(r'\d+', data['date'])[0]) == 1:
month = month + 1
date = str(month) + '月' + date
day_type = data['type']
high = re.findall(r'\d+℃', data['high'])[0]
low = int(re.findall(r'\d+', data['low'])[0])
if low < 10:
low = ' '+str(low)
temperature = str(low) + '-' + high
day_text = data['type']
if day_type == '阴' or day_type == '晴':
day_type = ' ' + day_type
try:
day_img = Image.open('..\\Requirement\\img\\small_weather_img\\' + day_text + '.png')
except FileNotFoundError:
day_img = Image.open('..\\Requirement\\img\\small_weather_img\\NA.png')
back_ground.paste(day_img, (47 + 52 * column, 57), day_img)
ttf = ImageFont.truetype(self.ttf_path, 10)
img_draw.text((49 + 52 * column, 94), temperature, font=ttf, fill=(255, 255, 255))
img_draw.text((49 + 52 * column, 45), date, font=ttf, fill=(183, 183, 183))
ttf = ImageFont.truetype(self.ttf_path, 15)
img_draw.text((50 + 52 * column, 106), day_type, font=ttf, fill=(255, 255, 255))
ttf = ImageFont.truetype(self.ttf_path, 16)
img_draw.text((51 + 52 * column, 29), week, font=ttf, fill=(255, 255, 255))
column = column + 1
day_type = data_today['type']
high = re.findall(r'\d+℃', data_today['high'])[0]
low = int(re.findall(r'\d+', data_today['low'])[0])
if low < 10:
low = ' ' + str(low)
temperature = str(low) + '-' + high
day_text = data_today['type']
try:
day_img = Image.open('..\\Requirement\\img\\big_weather_img\\' + day_text + '.png')
except FileNotFoundError:
day_img = Image.open('..\\Requirement\\img\\big_weather_img\\NA.png')
tem_now = json_weather['wendu']
if int(tem_now) < 10:
tem_now = ' ' + tem_now
tips = json_weather['ganmao'] # 插入换行符
tips = tips[0:21] + '\n' + tips[21:-1]
ttf = ImageFont.truetype(self.ttf_path, 14)
img_draw.text((58, 77), '℃', font=ttf, fill=(255, 255, 255))
img_draw.text((59, 94), day_type, font=ttf, fill=(255, 255, 255))
ttf = ImageFont.truetype(self.ttf_path, 39)
img_draw.text((18, 75), tem_now, font=ttf, fill=(255, 255, 255))
ttf = ImageFont.truetype(self.ttf_path, 12)
img_draw.text((22, 128), 'tip:' + tips + ' (天气仅供参考,请以实际为准哦qwq)', font=ttf, fill=(240, 240, 240))
img_draw.text((35, 109), temperature, font=ttf, fill=(255, 255, 255))
back_ground.paste(day_img, (18, 30), day_img)
back_ground.save('..\\file\\temp\\res.png')
if __name__ == "__main__":
a = WeatherApi()
print(a.get_weather('温州'))
a.img_crate(a.get_weather('温州'))结果
这段代码可以做到什么?它可以返回一个这样的图片

这段代码用到了python的pillow库这是一个图片绘制的库,但核心其实就是爬虫。
这是一个很初级的网络爬虫。
